The Falsifiability Method
In 60 seconds
Four principles — authorial position, audit discipline, structural-vs-cyclical, falsifiable description — naming the discipline behind the manuscript. The outputs are descriptions of regimes, not predictions of dates; named thresholds, not RAG colour-coding; cross-links to primary sources, not synthesised authority. What the method refuses — decision trees, dated forecasts, sentiment colour-codes, false-precision matrices — is what produces the discipline. The refusals are the method.
This document is about method, not about a thesis. The thesis is in two essays — The Math Doesn't Work and The End of the Bull Run — and it is not under revision here. What is under examination is the discipline both essays were written through. The method is the lens; this document makes the lens explicit so the lens itself becomes auditable.
Two disclosures. I write this from Cape Town — a South African chartered accountant looking at the United States from the outside. And I run Auto Alpha Advisory, an AI consultancy that automates professional-services work, which puts me, in the small, on the supply side of the labour displacement the manuscript describes. Neither makes me less interested in getting this right. Both are constraints the method imposes on the writer, then discloses so the reader can audit them.
The discipline starts visibly. The first verification pass on the signals dashboard, run in May 2026, found roughly twenty specific factual errors in numerics I had authored from training-data recollection — Schussler's birth year off by six years, V-Dem's 2009 peak off by both value and year, the 1950s productivity peak undershot by 1.6 percentage points, the 2008 EM credit spread peak off by 300 basis points.1 None of those errors was caught by looks right against my memory. All of them were caught by click through to the primary source and read the actual cell. That pass is the discipline being argued for here, applied to my own prior work. What follows articulates the discipline that produced the catch.
When I say method I do not mean a checklist. I mean the trained discipline an audit produces in the person who has done it for years — every claim sourced, every figure footnoted, every gap named — applied to the surfaces the manuscript walks: a sovereign balance sheet, an aggregate equity index, a population's household balance sheet, a series of unfunded entitlement promises whose accounting convention is most of the point. The training drilled out plausible-from-memory as a verification method. Plausible is not verified. The audit posture refuses the fourth option — leaving an unsourced claim in on the strength of how it feels.
The document refuses four moves explicitly, named here and then carried through the principles below rather than relisted.
| Refusal | What it refuses | Why |
|---|---|---|
| No decision trees | Branching probability diagrams that route the reader toward a recommended path | A confidence statement about the structure of the unknown the diagnosis is not entitled to make |
| No dated forecasts | Attaching a calendar year to a structural claim | The bear case has been correct on the math since 2021 and wrong on timing every year since — the method describes the regime and names the triggers, then declines to call the year |
| No RAG colour-coding | Red / amber / green sentiment labels on numeric thresholds | Collapses a numeric threshold into a sentiment label the threshold cannot earn — the false-precision move the audit trail exists to prevent |
| No 2-by-2 framings | Symmetric four-quadrant matrices that imply analytical symmetry | The presentation device overstates the confidence the underlying analysis can support |
Four principles, in order. Authorial position, because where you write from is part of the argument. Audit discipline, because how every claim is sourced is the document's load-bearing structure. Structural vs cyclical, because the math is structural and the timing is the question. Falsifiable description, because the output of the method is a description of a regime with named thresholds, not a prediction with a date attached. Each principle carries a sub-treatment and an Applied here callout — a cross-link to a concrete instance on this site where the principle is operational. If a principle's instance does not survive the click-through, the principle is not yet a method. The document closes with one worked example end-to-end — the V-Dem 2026 reading the verification pass surfaced — applied through all four principles in sequence.
1. Authorial position
The principle: where you write from is part of the argument. Every macro thesis has an authorial position; the method names it, discloses it in the opener, and lets the reader weigh it against the argument. The audit standard does not change with the vantage; what changes is which parts of the reader's cross-examination the writer should expect — and the writer who anticipates the cross-examination writes a more honest document.
1a. SA / Cape Town as vantage, not topic
The principle: South Africa appears as vantage, not as topic. The thesis is about the United States. SA is the position from which the analysis is written — the clinical-extreme test bed where the same arithmetic shows up with the buffer stripped out. Africa as topic belongs to a different book.
The vantage produces calibration the New York desk cannot. South Africa lived a version of the fiscal-credibility story the manuscript ascribes to the US — slow accumulation of debt against a shrinking productive base, credit-rating downgrades pricing in fiscal-dominance term premium, currency taking the strain when monetary credibility softens. The numerics on the US trajectory feel, from here, like the early stages of a film the SA viewer has already seen. That intuition is biased. It is also informative. The disclosure rule is to state the vantage in the opener and let the reader audit two things — which parts of the argument the vantage made stronger (the structural-debt math, the fiscal-credibility pricing, the EM-currency mechanics), and which parts the vantage may have weakened (the US policy-room argument, the institutional-resilience argument, the political-economy-of-the-cut argument). The frame, once named, gives the reader an audit trail. The unnamed frame is the false-objectivity move most macro writing performs by default; the method declines to perform it.
1b. The displacer-as-witness
The principle: when you write about a thing you also help create, you disclose it. Writing about AI labour displacement, when the writer runs a business that automates labour, is the position called displacer-as-witness. Not despite — because. The supply-side vantage is what the argument needs.
Writing about AI labour displacement from outside has two failure modes — alarmism, which over-weights worst-case projections without seeing how slowly substitution actually diffuses, and detachment, which treats the displacement as someone else's problem without naming the macroeconomic externality. The displacer-as-witness avoids both by writing the math from inside the supply side without softening it. The discipline this enforces is severe in one specific way: the writer cannot claim the displacement will affect someone else's labour, not mine. The displacer-as-witness has already chosen the deployment side. The cross-examination move the reader is owed — would you write this the same way if your business depended on the opposite conclusion? — is the move the disclosure pre-empts. The business already depends on the displacing conclusion. The disclosure therefore constrains the writer to write the math unsentimentally.
Stay on the accounting argument, not the moral one. The manuscript's claim is not that AI displacement is good or bad; it is that the bottom rungs of the white-collar career ladder are being removed first, which is the empirical observation Brynjolfsson's Stanford payroll-record finding documents and Goldman's labour desk corroborates. The moral question — what a society owes to workers whose career escalator just broke — is a different document. The accounting document goes first because it produces the numbers the moral document then has to negotiate with.
The displacer-as-witness is not a posture available to every macro writer. It is the only honest authorial position available to this one.
2. Audit discipline
2a. Audit posture
The principle: every claim sourced, every figure footnoted, every series named. Not as decoration. As discipline.
The practice. The Math Doesn't Work carries thirty-three footnotes across roughly seven and a half thousand words. The footnote density is not because the topic is academic. It is because the audit trail is the discipline visible. Any reader can audit any claim by clicking through to the named source. Anything the reader cannot verify against a primary source is not in the document. The constraint forces the writer to either find the source or to write the claim differently — to soften the assertion into the estimate it actually is, or to drop it altogether. Both responses are legitimate. The third response — to leave the claim in, unsourced, on the strength of plausible-from-memory — is the failure mode the training drilled out.
The mechanism on the site. The Watch Window dashboard at /where-are-we-going/signals carries 26 signals, each with a structured data_source block — provider, series id, endpoint, value format, last verified, fetchable. Not just FRED in the metadata: FRED, GFDEGDQ188S, federal-debt-held-by-public, monthly, 2026-04-30, fetchable: true. The schema is the discipline encoded. A signal cannot enter the dashboard until the data_source block resolves. If the source is an annual report PDF or a paywalled feed, fetchable: false is recorded explicitly so the reader can audit not only the value but the provenance class.
The Who watches this template. Each signal detail page names three to five specific analysts or institutions who track that exact metric, with a one-line annotation of why that source specifically. Not the general macro celebrities. Not Hatzius or Buffett in the abstract. Stephen Goss and Karen Glenn at SSA on the OASI projection. Dawie Roodt and Iraj Abedian on the SA fiscal trajectory. John Hussman on the Wilshire/GVA sister measure to cap-to-GDP. Maya MacGuineas at CRFB on the fiscal-gap framing. Naming is constraint. Once the watcher is named, the reader can audit the writer's reading of the watcher against the watcher's own published work.
The verification anecdote at the head of this document was an instance of this discipline applied to my own prior work. When the writer is about to make a claim that cannot be footnoted to a primary source, the writer stops. Three options: find the source, mark the claim as an estimate, or remove the claim. There is no fourth option. The trail is the posture made visible: the sourcing, the footnotes, the named series, laid out so the reader can check them. The writer who skips the trail is not running the posture; the writer who runs the posture has nothing on the trail to hide.
Applied here · Signal · Cap-to-GDP · Who watches thisUS Equity Market Cap / GDP — primary-source watchers
“Paul Tudor Jones — flagged 252% on his April 2025 Invest Like the Best appearance as the highest he had seen in his career. John Hussman — runs a sister measure (Wilshire/GVA) that adjusts for nonresidential capital structure; tracks both monthly.”
Read →2b. Gap-as-diagnosis
The principle: what is missing from a set of books is the finding. What two trustworthy sources disagree about is the diagnosis, not the noise. Audit training drilled this. Macro analysis, trained the other way, typically does not.
The instance from §4 of The Math Doesn't Work. Medicare HI — Part A, hospital insurance — has two depletion projections from the two institutions tasked with publishing them. The 2025 Trustees Report says 2033. The CBO says 2040.2 The same set of underlying conditions produces two answers, seven years apart. The macro-analyst training reads this as noise to be averaged or as a forecast range to be straddled. The audit training reads it as a finding. The seven-year gap is not the noise. The gap is the diagnosis. Each institution applied defensible methodology to defensible assumptions and reached different answers; what the gap names is that the methodology is at the limit of what the available data can support. The reader who knows about the gap knows more than the reader who has been given an averaged-out point estimate.
The Pending signal as method. The Watch Window has, at any point, several signals showing Pending — most recently the V-Dem US Liberal Democracy reading before the V-Dem 2026 release, the IMF COFER USD reserve share before the latest Q1 publication, the Treasury bid-to-cover series at year-turn. Pending is itself the diagnosis. Not we are missing data, but the most recent observation tells the reader the series has not been refreshed to the period in question. Pending signals are findings, not failures. They are findings about the refresh cadence of the underlying source. The signal that says Pending is the signal whose data_source block has the integrity to admit the absence.
The iceberg framing. The Math Doesn't Work develops the unfunded-entitlement liabilities at roughly thirty trillion dollars at the 75-year present value and over a hundred trillion dollars at the infinite horizon — multiples of the visible debt stock. The visible debt is the surface; the gap between the visible debt and the total unfunded obligation is the diagnosis. The gap is not omitted from the visible debt by accident; it is omitted by accounting convention. The convention is the finding. The audit posture asks the reader to look at the convention itself — to understand that the visible aggregate is the result of a methodological choice about what counts as a liability in this set of books, and that the unfunded obligation sits below the line because the convention places it below the line, not because the obligation does not exist.
The discipline. Train the reader to look for what is not there. The question audit training drills — what would I expect to see in this set of books that I am not seeing? — runs across signal selection, essay drafting, and the cross-examination of any consensus-supported claim. The same question is the one the Bottleneck Map will ask about industry consolidation; the same question is the one the Capability Stack will ask about labour-market exits. The gap-as-diagnosis principle generates the structural question; the structural question produces the analysis.
Applied here · Manuscript essay · §4 (Entitlement math)The Math Doesn't Work — the unresolved Medicare HI gap
“Medicare HI (Part A, hospital insurance): Trustees say 2033. CBO says 2040, a seven-year methodological gap on Medicare cost-growth assumptions that I do not think gets resolved in the optimistic direction.”
Read →3. Structural vs cyclical
The principle: the math is structural; the timing is the question. The aphorism runs through both manuscript essays. It distinguishes the diagnosis — which is true regardless of which year — from the trigger, which is unknown until it fires.
The accounting frame. Going-concern thinking from audit: when an auditor signs off on a set of accounts, the question is whether the entity can pay its obligations as they fall due. The answer is binary — yes, or yes with a material uncertainty. The material uncertainty is the structural condition. The going-concern audit names what has to be true for the entity to continue operating in its current form; it does not name the date the operations stop. The same separation applies to macro analysis. The fiscal arithmetic either supports the obligations or it does not; the year the inability becomes politically observable is a separate question, contingent on the cycle, on policy choice, on the discrete trigger that happens to fire.
Applied to macro. The US fiscal arithmetic does not work whether the trigger fires in FY2027 or FY2031. The maturity wall is the cleanest instance the manuscript names: about a third of marketable Treasury debt rolling at four-percent-plus in FY2026 alone, much of it issued in 2020–2021 at one-to-two-percent coupons.3 The refinancing is mechanical. The accounting event is on the books, on schedule, regardless of macro narrative. The cycle can soften the trajectory of interest cost; the cycle cannot remove the maturity wall. The cycle can mute the political pressure on entitlements; the cycle cannot reset the demographic ratio. The structural claim survives the cycle.
The error to avoid. Confusing the structural with the cyclical, in both directions. The business cycle producing two quarters of soft data does not refute the structural debt math. The business cycle producing two quarters of strong data does not refute it either. The math is not a function of the cycle; the cycle is constrained by the math. The bear case on the structural condition is invariant to the cycle; the bull case that the cycle will save the structural condition is the consensus error. Naming the structural claim makes the bull rebuttal harder to phrase, because it removes the cycle as a permitted defence.
The countervailing case. Structural arithmetic can be mis-applied. Not every claim about the math doesn't work is structural; some are cyclical claims dressed in structural clothing. The discipline is to name the books-of-account identity that produces the claim. Mandatory spending plus net interest already approximately equals total federal revenues. That is a structural identity — the discretionary budget is borrowed by accounting necessity, not by political failure, and no business cycle moves that identity off the page. Subprime auto sixty-day delinquency is at a 32-year high. That is a cyclical claim about credit-quality stress; it is real, but it is a function of the rate cycle on top of the household-balance-sheet structural condition, and the next cycle could move it. The method holds them apart so the writer does not over-claim and the reader does not over-discount.
The signals split. Structural series move on regime time: US debt-to-GDP, OASI depletion year, worker-to-beneficiary ratio, US fertility rate, housing cost-burdened renters, V-Dem US Liberal Democracy Index. Their movement is the regime change. Cyclical series — EM credit spreads, Treasury bid-to-cover, K-shape consumer spending share — are the marginal investor's reading of the structural regime at the current configuration. Both classes are meaningful. The method holds the two readings apart so the writer is not tempted to ride cyclical evidence into a structural conclusion or — the more common error — to ride cyclical-evidence absence into a refutation of a structural claim.
The math is structural. The timing is cyclical. The method describes both, and refuses to collapse the two into a single point estimate.
Applied here · Manuscript essay · §1 (Debt math)The Math Doesn't Work — the maturity wall
“About a third of all marketable Treasury debt matures in FY2026 alone, much of it issued during 2020–2021 at coupons of one to two percent and now being refinanced at four-percent-plus. This is not a forecast. It is a mechanical event in progress.”
Read →4. Falsifiable description
4a. Watch-window-with-falsification
The principle: every claim in the description carries a named threshold that would revise it. Not we will know more later but if X moves to Y, my read changes to Z. Falsifiability is built into the description itself, in the same paragraph as the description, not deferred to a closing caveat.
The operational instantiation. The Watch Window dashboard. Every signal has a numeric current_reading and a numeric set of thresholds — watch, alarm — with the meaning of each threshold spelled out alongside the number. No RAG colour-coding — red, amber, green is shorthand that collapses the numeric threshold into a confidence label the threshold cannot earn. The signal carries the number, the threshold, and the named mechanism that would resolve it. The reader can audit the writer's confidence by reading the position-in-range bar; the writer cannot retreat into the colour says concern, you know what that means because the writer did not publish the colour.
The per-signal template. Four sections every signal MDX page carries — Why this matters / Who watches this / Recent history / What would change my read — uniform across all 26 signals. The fourth section is structural to the method, not optional commentary. What would change my read is the falsifiability clause; without it, the description is unfalsifiable and the writer has no obligation to revise the read when the data moves. The writer cannot publish a signal page without writing the falsifiability clause. The discipline is template-enforced.
The Cap-to-GDP instance. The signal currently sits at 252% of GDP — the most extreme reading in the postwar series.4 What would change my read names the threshold (175%, the prior 2000 peak) AND the mechanism (a ~30% drawdown OR sustained nominal GDP growth above trend) AND a judgement on which mechanism is the historical resolution. That is what falsifiable description looks like — threshold, mechanism, and historical judgement, all named in advance of the resolution. If the index drops 30% in the next eighteen months, the writer's read does not change, because the conditions named in the falsifiability clause have been met. If cap-to-GDP stays above 200% for another five years on the strength of sustained nominal growth meaningfully above current trend, the writer owes the reader a revision of the read. Both outcomes leave a documented trail.
Applied here · Signal · Cap-to-GDP · What would change my readUS Equity Market Cap / GDP — falsifiability statement
“A return to the 175% band — the prior 2000 peak — would require either a ~30% index drawdown or sustained nominal GDP growth meaningfully above current trend. The historical resolution mechanism for cap/GDP this extreme is the former, not the latter.”
Read →4b. Regime + triggers, not dates
The principle: describe the regime; name the triggers; refuse the dates. Long-form theses are about describing structural configurations and the events that would shift them. They are not about predicting when the events will fire.
Why dates are a confidence trap. The bear case on US equities has been correct on the math since 2021 and wrong on timing every year since. Anyone who acted on a dated prediction lost money — the 2022 drawdown was followed by the 2023–2025 melt-up that compounded enough to leave the dated bear underwater on a five-year window. Anyone who described the regime — extreme valuations on every measure with historical correlation to forward returns, mechanical bid from passive flows compounding the regime, structural household-balance-sheet weakness that would absorb the unwind asymmetrically — and named the triggers that would change the read on each, is on the record correctly. The math is the same; what differs is whether the writer was confident enough to attach a year. The method's instruction is to refuse the year.
The regime + triggers output. The Math Doesn't Work names six forces and the triggers that would change the read on each. The End of the Bull Run names the watch triggers for the mechanical bid — cap/GDP returning to 175%, the Mag 7 concentration breaking, the required-minimum-distribution curve crossing the passive inflow. Neither essay says the unwind starts in 2027. Both essays say here is what the regime looks like, here are the named events that would change the read, here is the dashboard where the named events get tracked in real time. The reader holds the dashboard and adjusts as the named events fire — not as the calendar advances.
The temptation as tell. When the writer is tempted to add a date — because adding a date would make the claim more memorable, more shareable, more concrete — the writer notes the temptation and writes the regime instead. The temptation is a tell. The writer who wants to add a date wants to make the claim land harder than the evidence supports. The method's instruction is to refuse the over-claim.
The I have been wrong every year since 2021 disclosure. Honest authorial position when the writer has held the bear math for years and not called the year. The writer does not pretend to have the timing; the writer states that the timing is unavailable; the writer describes the regime; the writer lets the reader decide what posture is appropriate. The posture decision is the reader's. The writer's job is to render the regime accurately enough that the posture decision is well-informed.
One specific consequence. The bear thesis cannot be vindicated by a single dated event. The thesis is vindicated only by the regime persisting through the dashboard's named triggers firing — or refuted by the dashboard's named triggers failing to fire over a sufficiently long window. The horse-race framing — was 2026 the year of the crash, or did the bulls win? — is the framing the method refuses. The method's question is whether the regime is what was claimed.
Applied here · Manuscript essay · The End of the Bull Run · OpenerThe End of the Bull Run — the refusal of dates
“I have held some version of the bear position on US equities since 2021. I have been wrong on timing every year since. I am not going to call the date. I am going to describe the regime, set out the math, and let the reader decide what posture is appropriate to it.”
Read →A worked example — V-Dem, 0.75 → 0.57
End-to-end demonstration of the method on a single signal: the V-Dem 2026 release dropping the 2025 US Liberal Democracy Index from 0.75 to 0.57.5 The four principles, applied in sequence, against one observation.
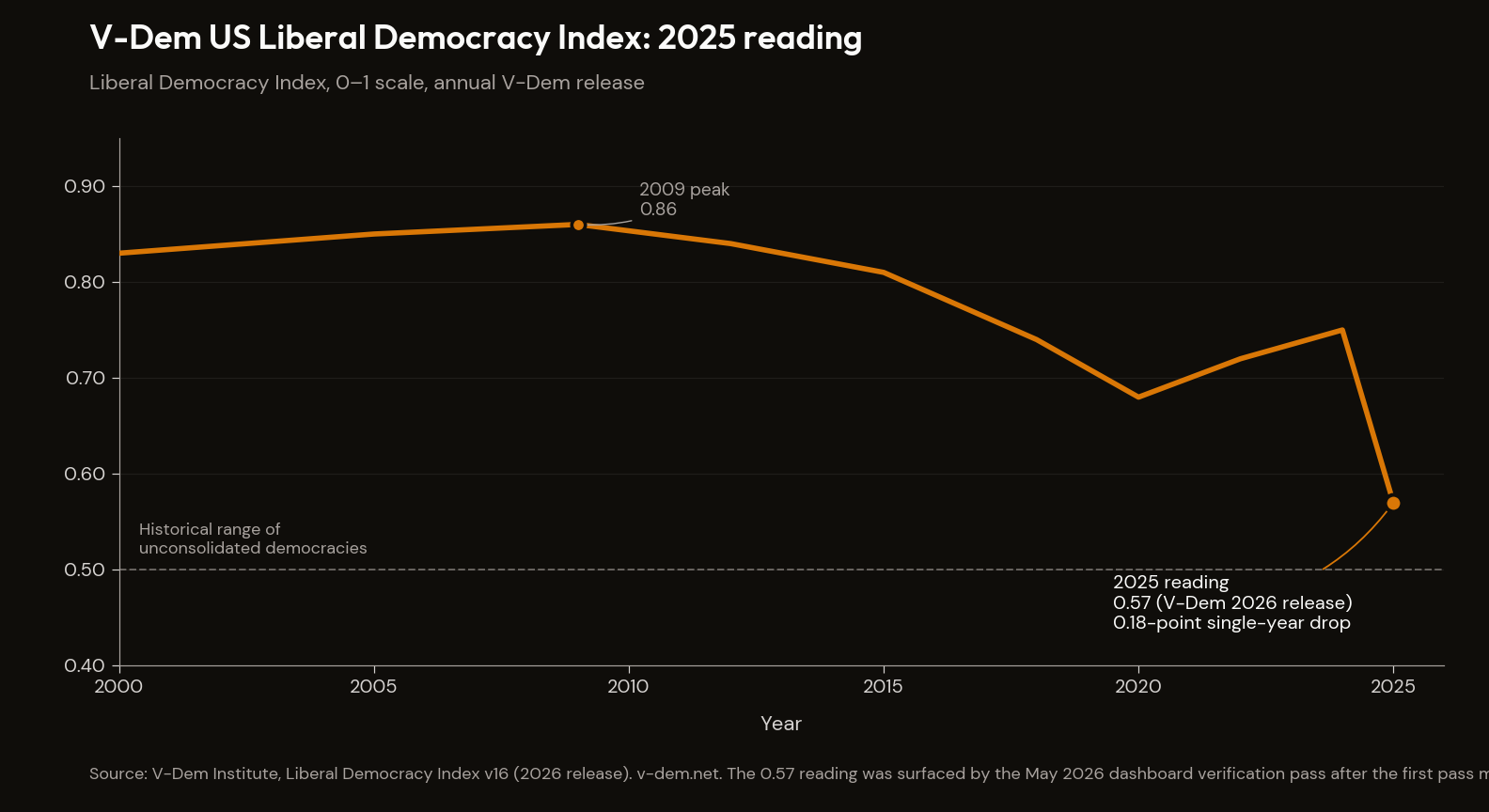
1. Audit posture surfacing the source. The first verification pass on the signals dashboard used open WebSearch for primary-source verification and missed the V-Dem 2026 release entirely. The second pass, given explicit V-Dem URLs and instructed to fetch the 2026 dataset specifically, surfaced the corrected 2025 reading. The audit posture, scaled up by named-URL discipline, was what produced the correction. The first pass was plausible-from-memory dressed as primary-source check; the second pass was the actual primary-source check. The difference between the two is the discipline this document is articulating.
2. Gap-as-diagnosis on a methodological surface. The V-Dem signal had carried Pending in the dashboard before the 2026 release. Pending was itself the diagnosis — not we are missing data but the most recent observation tells us the series has not been refreshed to the 2025 period yet. The signal's status was the finding about V-Dem's publication cadence; the writer who interpreted Pending as a placeholder waiting for the real number misunderstood what Pending was carrying. Pending was the real number.
3. Structural vs cyclical on a single-year drop. A 0.18-point single-year drop on the Liberal Democracy Index is, in V-Dem's full history, an extremely large movement. The question the method has equipment to ask is: is this cyclical — a single-year overshoot that the next reading will partially reverse — or structural — the regime crossed an institutional threshold the series will encode at the new level? The method does not have a definitive answer at the time of reading. It has the discipline to hold the question open and to name what would resolve it.
4. Falsifiable description producing the next read. The What would change my read section on the V-Dem signal page names the resolution conditions — a 2026 reading reverting to the 0.70 band would be cyclical evidence; a reading at 0.50 or below would be structural confirmation that the US has entered the historical range of unconsolidated democracies. Both directions are named. The threshold is numeric. The description is falsifiable. The next observation produces the next read, not the writer's prior expectation.
The method does not produce the V-Dem call. It produces the conditions under which the call would change.
The Watch Window is where the method is operational. The manuscript essays — The Math Doesn't Work and The End of the Bull Run — are where it has been deployed against the live diagnosis. Everything that follows in this section — the Bottleneck Map, the Capability Stack, the Scenario Playbooks — is the method applied to a different surface.
Footnotes
-
First verification pass conducted May 2026 against the signals dashboard at /where-are-we-going/signals. Primary sources used to resolve the errors named here: V-Dem 2026 dataset release (v-dem.net); BLS Major Sector Productivity series; JP Morgan EMBI Global series; public biographical record. Specific corrections logged in each signal page's source notes. ↩
-
Social Security and Medicare Boards of Trustees, 2025 Annual Report (Medicare HI Trust Fund depletion projection: 2033); Congressional Budget Office, Long-Term Budget Outlook 2025 (Medicare HI depletion projection: 2040). The seven-year gap reflects differing assumptions on Medicare cost-growth trajectories rather than differing underlying data. ↩
-
US Treasury Office of Debt Management, quarterly refunding presentation; Committee for a Responsible Federal Budget analysis of FY2026 refinancing schedule. The coupon comparison reflects observed yield differentials between 2020–2021 issuance and current refinancing levels. ↩
-
Wilshire 5000 Total Market Index divided by US nominal GDP, sourced via FRED series WILL5000IND and GDP. Paul Tudor Jones flagged the 252% reading on his April 2025 Invest Like the Best appearance as the highest he had seen in his career; the prior 2000 peak was ~175%. ↩
-
V-Dem Institute, Liberal Democracy Index v16 release (2026), US series. The 0.75 → 0.57 single-year movement was surfaced in the May 2026 dashboard verification pass with explicit primary-source URL instructions, after the first pass (relying on open WebSearch) missed the release entirely. ↩