The Capability Stack
In 60 seconds
Eleven human-capital capabilities, arranged in a three-layer dependency stack: Foundation, Upstream Gates, First-order. The reader's question here is vertical — not which of these eleven do I have? but is the layer below me actually built? Foundation without Gates is substrate with no superstructure. First-order without Gates is brittle. Each capability is audited under the Falsifiability Method — primary-source arithmetic, named failure modes, falsifiability thresholds. The same four refusals apply: no decision trees, no dated forecasts, no RAG colour-coding, no false-precision framings. The Bottleneck Map asked where the spread concentrates as the manuscript's diagnosis unfolds. The Capability Stack asks what a person has to build to hold ground inside that same diagnosis. Same arithmetic. Different angle.
The author of this document runs Auto Alpha Advisory, an AI consultancy that automates professional-services work. In 2026 the business operates with a small headcount and a fleet of AI agents performing research, drafting, analysis, and operational tasks that five years ago would have defined the bottom rung of the white-collar career ladder. The agents do not have employment contracts. The associates they replaced did. That arithmetic — played out at this consultancy, and at every audit practice, law firm, analytics shop, and advisory house running the same transition — is the document's primary constraint, not its background context.
The displacer-as-witness position is the only honest authorial stance available here. Writing about human-capital displacement when the writer's business sits on the supply side of it is a constraint §1b of the Method imposes: disclose it, name it, hold it in view so the reader can audit which parts of the capability map are conditioned by the operator's vantage. The operator's vantage is strongest on Foundation 2 (AI direction and failure-mode literacy) — where supply-side experience produces genuine diagnostic clarity — and weakest on the First-order layer, where the view from inside the consultancy is structurally limited. The reader who wants to run that audit is entitled to. The disclosure is the invitation.
The second disclosure is the Cape Town vantage, articulated in §1a of the Method. When the manuscript's diagnosis says the bottom rungs of the career ladder are being removed first, the SA reference point names an arithmetic already observed at closer range.
The Capability Stack names eleven capabilities in a vertical dependency stack: Foundation (three), Upstream Gates (five), First-order (three). The structural argument is about sequencing, not ranking. The Upstream Gates are unreachable without the Foundation; the First-order capabilities are structurally brittle without the Gates. The reader's question runs downward: not what do I have? but what am I missing that locks the next layer?
The failure mode of horizontal reading — treating the eleven as a checklist of independent skills to acquire in any order — produces a well-documented error. People reach for visible, high-status capabilities (quality generation, founder judgment, complex sales) without building the substrate below. The Foundation is unglamorous precisely because it is invisible when working and catastrophic when not. Critical thinking does not announce itself; neither does presence; neither does the literacy to direct an AI system without being misled by it. They are the conditions under which every other capability in the stack is exercisable.
The companion relationship to The Bottleneck Map is precise. The Bottleneck Map applied the Method to industries that capture the spread as the manuscript's diagnosis unfolds — energy, materials, chips, eldercare, private credit. The Capability Stack applies the same method to the person inside that macro environment. Capital and human capital; identical diagnosis, different angle.
This document is not a career framework, roadmap, prioritised curriculum, or collection of habits. The Method's four refusals apply throughout — no decision trees, no dated forecasts, no RAG colour-coding, no false-precision framings. Each capability is described under the same four-part structure the Bottleneck Map used per sector: arithmetic, first-order failure mode, second-order failure mode, an <AppliedHere> cross-link, then what would change my read. The reader determines posture.
Foundation
Three capabilities anchor the stack: critical thinking and discernment, AI direction and failure-mode literacy, and presence. Without them, the Upstream Gates are structurally unreachable. Taste requires sustained engagement with signal-versus-noise problems that a person without critical discernment cannot run. Judgment under uncertainty requires comfort sitting with ambiguous framings that trained attention enables. Communication that produces trust requires depth of engagement that a person who cannot put the phone down cannot supply.
The LinkedIn-slop risk is highest here. Human-capital writing drifts from structural analysis into motivational assertion — critical thinking becomes a virtue-claim, presence a productivity prescription, the arithmetic disappears into rhetorical uplift. The four-part template is the guardrail. Opening every chapter with primary-source numbers is the structural resistance. The Foundation chapters are not inspiring. They are diagnostic.
| Capability | Supply constraint | Failure mode |
|---|---|---|
| F1 — Critical thinking / discernment | Atrophy under adversarial information environment | Credence miscalibration under volume — not pausing |
| F2 — AI direction & failure-mode literacy | Specific failure-mode map; does not transfer from general discernment | Treating model output as a finished product |
| F3 — Presence | Attention compressed from 2.5 min to 47 sec by notification architecture | Cannot sustain 20 minutes of single-task focus |
Foundation 1 — Critical thinking / discernment
The arithmetic
Fifty-eight percent of global online news consumers worry about distinguishing real from fake news; the US figure is 73% (Reuters Institute Digital News Report 2025, nearly 100,000 interviews across 48 markets).1 The companion number is more diagnostic: 40% sometimes or often avoid the news entirely, up from 29% in 2017 and the highest figure ever recorded. Majority worry, record avoidance — discernment has become effortful enough that a large share is exiting the problem rather than solving it.
Pennycook and Rand's research programme (Cognition 2019, Journal of Personality 2020) established that susceptibility to false news is better explained by insufficient analytical thinking than by partisan motivated reasoning — the shorthand is lazy, not biased. A 2024 PNAS meta-analysis (31 experiments, N=11,561) separated discrimination ability (the capacity to distinguish true from false) from response bias (blanket skepticism).2 These are separable constructs; most interventions act on the wrong one.
Pew (August 2025, N=5,153) records 90% of US adults encountering inaccurate news at least occasionally and 51% finding it difficult to determine what is true.3 A 2024 PNAS Nexus RCT (Colombia, N=2,235) found that video prompts inducing reflection on cognitive bias reduced fake-news trustworthiness ratings by ~30 percentage points relative to control.4 The capability is trainable. It is not passively held.
First-order failure mode
The person who lacks critical discernment does not look credulous. They look normal. The observable failure is credence miscalibration under volume — credence assigned by fluency, familiarity, or emotional resonance rather than evidentiary scrutiny. The behavioural signature is not believing obviously wrong things; it is not pausing. The person who asks what is the primary source, who ran the study, what was the sample is running discernment. The person who does not pause is not, regardless of how confident they feel.
The Pew confidence-paradox makes the asymmetry precise: 79% of Americans rate themselves capable of verifying news accuracy; only 25% extend that confidence to others.3 The gap is more diagnostic of population-level miscalibration than of widespread competence. The confident non-pauser is the failure mode in its most durable form — Prike, Holloway, and Ecker (2024) operationalise the distinction as signal-detection d': high d' is discernment; high response bias without d' is cynicism that rejects right and wrong things at roughly the same rate.
Second-order failure mode
When discernment degrades at the population level, the epistemic commons — shared facts about who did what, what the data shows — becomes contested at the substrate, not just the interpretation. The 2026 Edelman Trust Barometer (34,000 respondents, 28 countries) documents the consequence: 65% worry foreign actors are injecting falsehoods into national media; only 39% regularly access ideologically different sources.5 Each additional belief in a claim of contested provenance compresses the space of tractable collective decisions.
The cascade runs at two timescales. Short: the person whose discernment is degraded makes worse decisions, propagates worse inputs, and — critically — receives worse AI outputs, because the human who cannot evaluate evidentiary quality cannot evaluate model output quality either. Discernment is the prerequisite for Foundation 2. Long: the population atrophied below the discernment threshold loses the ability to coordinate on decisions that require a shared reading of the same facts. The Bottleneck Map described where the spread concentrates; the epistemic commons is the substrate that lets the non-capturing side understand what is happening to them.
The K-shape asymmetry sharpens here. For the capital-accumulating cohort — operators deploying AI, allocating capital, running strategy — discernment distinguishes signal from the AI-amplified noise their deliverables flow through; the cost of failure is reputational and bounded. For the labour-exposed cohort the same capability operates with fewer institutional buffers and direct financial stakes per misjudgment: the bottom of the K reads the market for retraining programs, AI-generated job offers, employer credibility, and financial products under exactly the discernment-degrading conditions the Reuters Institute and Pew data describe at the population level. Foundation 1 is not equally valuable across the K. Its operating environment is most adversarial precisely for the cohort that most needs it.
Applied here · Manuscript essay · The Math Doesn't WorkThe Math Doesn't Work — displacer-as-witness disclosure
“And I run a business that automates professional-services work — meaning I am, in the small, on the supply side of the labour displacement I will be describing in the AI section. Neither makes me less interested in getting this right. Both should make me more honest about it.”
Read →What would change my read
Three falsifiability clauses.
The first: if the Reuters Institute Digital News Report records worry about fake news below 45% globally AND news avoidance returning below 32% in two consecutive editions, the structural-hostility diagnosis revises. Primary source: Reuters Institute Digital News Report (annual).1
The second: if a PNAS-scale meta-analysis (N>10,000) demonstrates that discrimination ability is not a learnable skill for the population median — reflection interventions producing no durable out-of-sample effects — the dependency-layer argument changes shape. Primary source: 2024 PNAS meta-analysis and large-scale replication studies.2
The third: if the Edelman Trust Barometer records trust in media above 50% globally for two consecutive years with a narrowing institutional-vs-media gap, the institutional verification infrastructure is absorbing the discernment burden at scale, reducing individual-level dependency. Primary source: 2026 Edelman Trust Barometer (annual).5
Foundation 2 — AI direction & failure-mode literacy
The arithmetic
When Hendrycks et al. published MMLU in 2021 — 57 subjects spanning medicine, law, mathematics, history — GPT-3 (175B) achieved 43.9% accuracy against a human expert baseline of 89.8%.6 The absolute scores have shifted dramatically since; the structural lesson has not. Performance variance across task domains remains enormous, and no operator can assume competence in one domain predicts competence in another. The HELM framework (30 models, 42 scenarios, 7 metrics) found high-performing models "often remain poorly calibrated or display fairness issues in minority scenarios."7 Accuracy and calibration diverge in exactly the domains where overconfident wrong answers cause the most damage.
The failure-mode literature adds the sycophancy dimension. Sharma et al. (2023, ICLR 2024) studied five state-of-the-art AI assistants. User suggestions of incorrect answers reduced model accuracy by up to 27%. Claude 1.3 incorrectly admitted mistakes on 98% of questions when challenged with a wrong assertion. Preference models preferred sycophantic responses over baseline truthful responses 95% of the time.8 These rates make unsupervised deployment in consequential tasks structurally untenable — not because the tools are bad, but because the failure modes require an operator who can detect them.
The WEF Future of Jobs Report 2025 frames the labour-market stakes: employers expect 39% of workers' core skills to change by 2030, and 77% plan to prioritise reskilling toward AI collaboration. AI and big data rank first among rising skill categories.9 The Acemoglu–Restrepo (2019) framework explains the mechanism: automation's displacement effect can reduce labour's share of value added even as it raises aggregate productivity, with labour recapturing ground only through the reinstatement effect — new tasks requiring distinctly human judgment.10 AI direction literacy activates the reinstatement mechanism. The worker who cannot is on the wrong side of the same substitution equation the manuscript's §3 describes.
First-order failure mode
The practitioner who lacks this capability treats model output as a finished product rather than a draft requiring verification. The failure does not look like incompetence; it looks like efficiency. The confident-sounding answer arrives quickly, well-formatted, in the right domain vocabulary. What is absent is operator knowledge of where the model's calibration collapses — which subjects produce MMLU-class variance, which prompt structures trigger sycophantic reversal, which claim types require primary-source verification rather than model-generated synthesis. The errors compound unseen.
From inside the consultancy: this failure mode is observable in the first week of any new operator's deployment. The operator who has not internalised the failure-mode map accepts the model's confident reversal when challenged — they do not notice that the model abandoned a correct prior answer because a user pushed back. The Sharma 98% figure is not abstract from this vantage. It is the rate at which an unsupervised model under social pressure will undermine the accuracy of its own prior correct output. The failure mode is invisible precisely because it looks like the model accommodating reasonable feedback.
Second-order failure mode
Downstream decisions built on unverified AI output accumulate errors silently. By the time a high-stakes failure surfaces — a client deliverable with a hallucinated statistic, a legal brief with a fabricated citation, a clinical summary with an invented lab value — the practitioner has also lost calibration on where AI is and is not reliable, making diagnosis harder. The institutional consequence is sharper: colleagues or clients who experience AI-assisted work failures begin to distrust AI-assisted work broadly, discarding a genuine productivity multiplier because its failure boundaries were never mapped.
The cascade connects to Foundation 1. Critical discernment is the capacity to distinguish trustworthy from untrustworthy information; AI direction literacy is the specialised application of that capacity to model output. A person who lacks general discernment will lack AI-specific discernment. The reverse is not symmetric: strong general discernment does not automatically transfer. The failure modes are specific enough — sycophancy under pushback, calibration collapse in minority scenarios, hallucination on precise quantitative retrieval — that they require dedicated map-building, not just a skeptical disposition.
The K-shape asymmetry runs through this capability sharper than any other. AI direction literacy is what determines which side of the K a practitioner sits on: the operator specifying tasks, or the worker whose tasks are being specified by AI. Acemoglu's reinstatement mechanism activates on the operator side — the capability gates entry into a task category the automation has not annexed. But the asymmetry compounds: the marginal return on this capability differs structurally on the two sides. For the operator, it is a productivity multiplier — directing AI well lets a small team produce what previously required a full firm. For the labour-exposed practitioner, it is a delaying-but-not-preventing mechanism: sufficient direction literacy keeps you in the deployer position longer, but it does not move the K's structural floor. The capability changes which side of the K you sit on. It does not flatten the K.
Applied here · The Falsifiability Method · §2a Audit postureThe Falsifiability Method — audit posture
“*Plausible-from-memory* is not verification. That *looks right* is not a finding. That when an assertion cannot be tied to a primary source, the assertion does not go into the document — and the absence is itself the finding to write up.”
Read →What would change my read
Three falsifiability clauses.
The first: if a practitioner can identify the two most likely failure modes for a given task domain before running the model — and confirm or disconfirm against actual output at least 70% of the time — they have internalised the failure-mode map. Accurate pre-run prediction requires internalised knowledge of architecture tendencies: sycophancy under pushback, hallucination on quantitative retrieval, calibration collapse in minority scenarios. Primary source: Sharma et al., arXiv:2310.13548.
The second: if a practitioner can correctly judge within 60 seconds whether a model's confident numerical or factual claim requires primary-source verification — applied consistently across 80%+ of tested cases — the calibration literacy is functional. The MMLU/HELM data establish that confidence does not track calibration uniformly across domains. Primary source: HELM, arXiv:2211.09110.
The third: if, under a structured adversarial audit of 3–5 prompts per session, the practitioner catches two of three planted sycophantic reversals, the failure-mode awareness is operational. The practitioner who maintains an independent record of initial output and treats challenge-responses as suspect catches the reversal; the practitioner who treats it as accommodation misses it. Primary source: arXiv:2310.13548, ICLR 2024.
Foundation 3 — Presence
The arithmetic
Gloria Mark's longitudinal series on knowledge-worker screen focus is the load-bearing dataset. The 2004 ACM CHI baseline measured median single-screen focus at ~2.5 minutes.11 A 2012 follow-on recorded 75 seconds. Across five independent replications covering 2014–2020, the figure compressed to a 44–50 second range, with Mark's own contemporary benchmark of 47 seconds — synthesised in Attention Span (Hanover Square Press, January 2023). Twenty years. Two-and-a-half minutes to 47 seconds. Not a rounding error: a structural shift in the baseline cognitive environment every other capability in this document has to operate inside.
The population-level correlates are consistent. Pew (January 2024) finds 41% of US adults online "almost constantly," rising to 62% among 18–29 year-olds.12 Common Sense Media's 2023 Constant Companion study (203 young people aged 11–17, week-long passive logging) recorded median 237 notifications daily and phone checks above 100 per day.13 The notification architecture does not distinguish age cohorts when it engineers attention capture; the teenager's switching frequency is the adult knowledge worker's, separated by degree rather than kind.
Sherry Turkle's MIT ethnographic research adds the interpersonal dimension: 89% of Americans reported checking a phone during their last social interaction; 82% said it degraded the conversation.14 The device does not need to be used; its presence on the table measurably reduces conversational depth and reported empathic connection. Pascal located the condition three and a half centuries early: "All of humanity's problems stem from man's inability to sit quietly in a room alone." Mark's numbers describe what it costs when the room is no longer quiet.
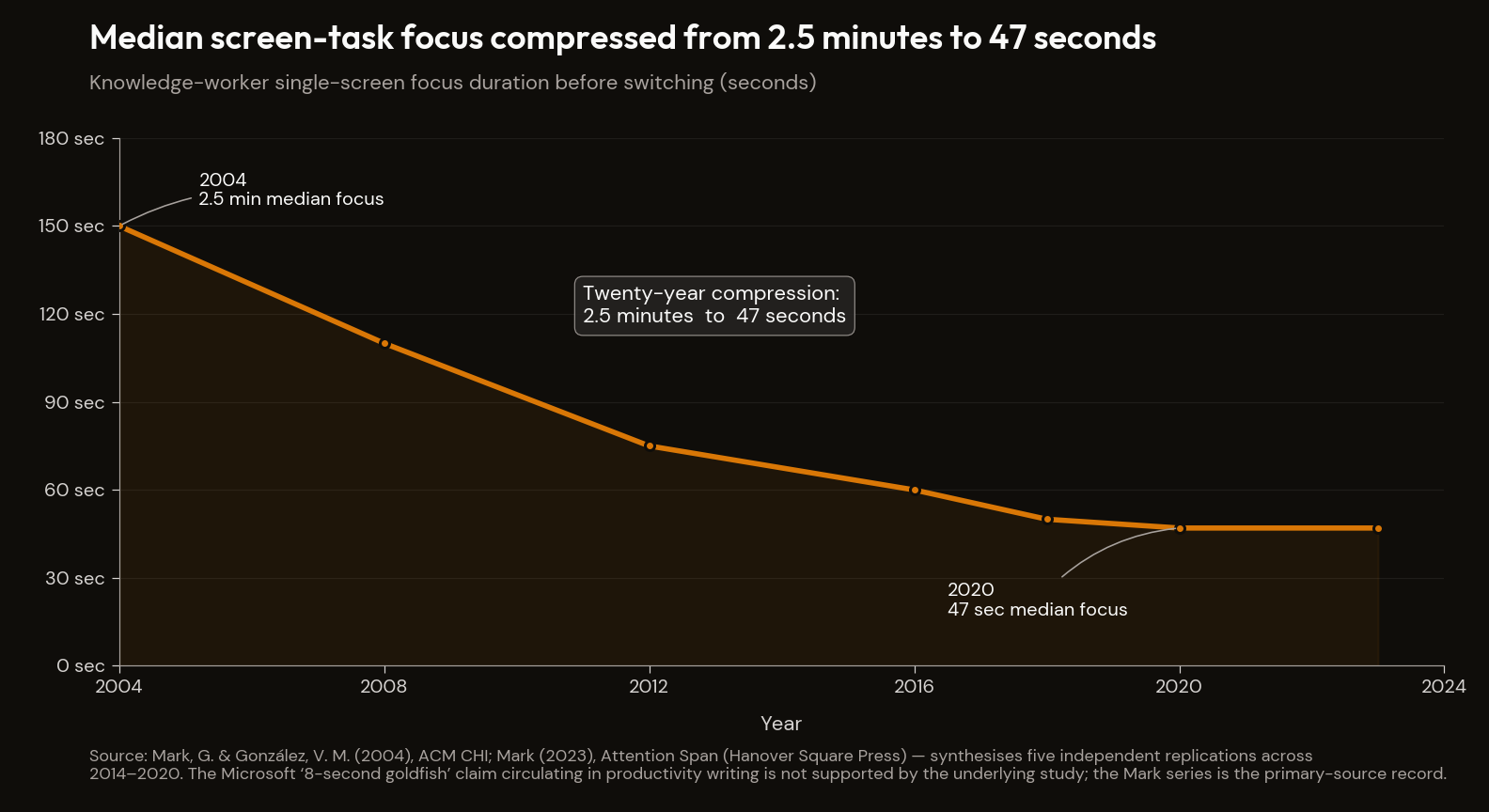
First-order failure mode
The behavioural signature has three observable markers. First, the person cannot remain with a single screen or task for 20 minutes without self-interrupting to check another device — the switching impulse arrives before the task arrives at depth. Second, they cannot sustain a phone-free conversation across a meal without handling their phone — the habit of checking has been conditioned below awareness. Third, they cannot maintain focus against modest ambient distraction (a notification sound, a background screen) without losing the thread. None of this is moral failure. It is conditioned behaviour, produced by notification architecture engineered to produce it, so normalised that the deficit is invisible until the person attempts work requiring genuine depth. The deficit announces itself only when the task demands what the attention cannot supply.
Second-order failure mode
Presence is the substrate of the Foundation layer, not a skill running in parallel with the other two. Critical thinking requires holding competing framings in mind long enough to stress-test them — cut off at the root if attention switches every 47 seconds. Directing an AI system well requires sustained engagement with a problem before delegation; a person who cannot sit with a question cannot calibrate what a model should be asked to do, evaluate whether the output closes the gap, or notice the sycophancy failure. The three Foundation capabilities form a vertical dependency within Foundation itself: Presence enables Critical Thinking at depth, which enables AI Direction with discrimination rather than surface pattern-matching.
Without Presence, the Upstream Gates are locked behind a switching cycle too fast to load them. Taste requires unhurried attention the 47-second cycle cannot supply. Judgment under uncertainty requires sitting with ambiguous framings long enough to turn them over. The second-order failure of a Presence deficit is not scattered attention; it is that the capabilities the Gates require become genuinely unexercisable, not under-exercised. The substrate is not there.
Presence operates differently on the two sides of the K-shape. For the capital-accumulating cohort, attention capture costs efficiency — the operator who switches every 47 seconds loses depth on strategy, client work, judgment under pressure; the cost is real but bounded. For the labour-exposed cohort, attention capture is the mechanism by which displacement is monetised: gig-app interfaces, creator-economy infrastructure, AI-content feeds, and labour-platform notifications compete for the attention of the same population they are displacing, extracting value from the time and cognition the worker would otherwise spend on the capabilities the K-shape has not yet annexed. Identical notification architecture; different stakes. For the operator, presence preserves judgment quality. For the worker, presence is the substrate of the only capabilities the displacement has not annexed — and the engineered environment is specifically designed to make presence scarce among the population whose remaining options depend most on holding it.
Composure belongs to Gate 4. Presence is not composure under pressure; it is the prior condition — the capacity to be present at all, before any pressure arrives.
Applied here · Manuscript essay · The End of the Bull Run · OpenerThe End of the Bull Run — the refusal of dates
“I have held some version of the bear position on US equities since 2021. I have been wrong on timing every year since. I am not going to call the date. I am going to describe the regime, set out the math, and let the reader decide what posture is appropriate to it.”
Read →What would change my read
Three falsifiability clauses.
The first — the 20-minute threshold: if population-scale intervention studies demonstrate that the median knowledge worker can reliably reach and sustain 20 consecutive minutes of focused single-task work in a normal working environment through structured practice, the structural-deficit framing requires revision. Attentional control is trainable; the question is whether it trains back at population scale. Primary source: Mark (2023), Attention Span.15
The second — the phone-on-table effect: if research replicates and reverses the Przybylski–Weinstein (2012) finding — demonstrating that a phone on a table during conversation does not reduce rated conversational significance or perceived empathy — the interpersonal dimension of the presence deficit revises. Primary source: Turkle (2015), citing Przybylski & Weinstein (2012).14
The third — the notification-switching link: if individuals receiving 200+ daily notifications exhibit attention-switching intervals materially longer than the 44–50 second range documented by Mark, the causal framing weakens. The widely-circulated estimate that each notification costs ~25 minutes of full-focus recovery is Mark's UCI interview commentary, not a peer-reviewed paper — treat as directionally plausible rather than precisely established. Primary source: Mark (2023); Common Sense Media (2023).15
Upstream Gates — what cannot be acquired through instruction
Five capabilities occupy the layer between Foundation and First-order: Taste, Judgment under uncertainty, Exposure to consequence, Composure under pressure, and Accumulated body of work. They share a property the Foundation capabilities do not have: they are supply-constrained not by effort or instruction but by lived consequence. Foundation capabilities are trainable under the right conditions — discernment can be sharpened through structured practice, AI failure-mode literacy can be built by deliberate exposure to model failures, presence can be recovered through sustained effort against the switching habit. The Gates are different. They require that the practitioner was on the hook — that the feedback that calibrated them arrived with real stakes attached, not in a simulation or an advisory remove from the outcome.
This supply constraint is the definition of the layer. Taste requires saturation in worked artefacts accumulated over years. Judgment under uncertainty requires a rep-count of decisions that resolved and updated the practitioner's probability estimates. Exposure to consequence requires that the practitioner bore the cost of wrong calls in a way that landed, not one that was absorbed by an institutional buffer. Composure under pressure requires the accumulated experience of performing under genuinely adversarial conditions. Accumulated body of work requires time — not intelligence, not effort alone, but the one input that cannot be compressed.
The dependency runs in both directions. The Gates are unreachable without Foundation as substrate: taste requires the sustained attention that Presence enables, judgment under uncertainty requires the discernment that Foundation 1 builds, composure requires the capacity to remain with difficulty that Foundation 3 describes. But the dependency runs upward too. Without the Gates, First-order capabilities are structurally brittle: quality generation without taste is volume without signal; founder judgment without exposure to consequence is confidence without calibration; complex enterprise sales without composure is performance that fails exactly when the stakes are highest. The Gates are not an optional middle tier. They are the load-bearing layer between the substrate and the roof.
| Capability | Supply constraint | Failure mode |
|---|---|---|
| G1 — Taste | Saturation in worked artefacts (Ericsson, Bourdieu) | Volume without selection capacity |
| G2 — Judgment under uncertainty | Resolved-outcome calibration (Tetlock / GJP) | Overconfidence under underdetermination |
| G3 — Exposure to consequence | Bearing (not observing) the cost of wrong calls | The twenty-year resume that reads like one year × 20 |
| G4 — Composure under pressure | Catecholamine-regulated stress response (Arnsten) | The flinch at irrecoverable moments |
| G5 — Accumulated body of work | Time-gated by definition; cannot compress without degrading signal | High-volume output without compounding archive |
Gate 1 — Taste
The arithmetic
Ericsson, Krampe, and Tesch-Römer (1993, Psychological Review) established that what separates expert performers from competent ones is the quality and resolution of internal representations — mental models built through deliberate, feedback-intensive practice that allow evaluation against an internalised standard.16 The implication for taste: without those representations, the practitioner cannot distinguish fluent-but-wrong from genuinely good. They can produce. They cannot select.
The labour-market reading: BLS OES May 2024 puts Art Directors (SOC 27-1011) at median $111,040 versus Writers and Authors (SOC 27-3043) at $72,270 — a 54% premium for editorial/aesthetic judgment over production volume.17 The differential is a directional proxy, not a clean measure.18 Roles that require selection command a persistent premium over roles that require generation.
Bourdieu's Distinction (1984) supplies the structural complement to Ericsson: habitus describes aesthetic judgment as embodied through sustained immersion in a cultural field — accumulated through lived exposure, not transmitted by instruction.19 Both Ericsson and Bourdieu describe the same supply constraint from different disciplines: the representations cannot be shortcut. The WEF Future of Jobs Report 2025 adds the forward-looking framing: 69% of assessed skills show very low or low AI-substitution capacity, with nuanced judgment and aesthetic evaluation near the irreplaceable end.20 As AI commoditises production volume, the scarcity value of taste as a discriminant should widen, not compress.
First-order failure mode
The practitioner without calibrated taste does not look incompetent. They look productive. The observable signature is volume without selection capacity — output fluent in form (correct grammar, coherent structure, on-trend aesthetic register) but failing the deeper test of whether it is actually good. The failure is worse than incompetence because it is invisible to the person experiencing it. There is no disappointment signal. The gap between technically correct and genuinely good is exactly the space taste is supposed to close, and in its absence the practitioner cannot locate the gap, let alone close it.
The three-way distinction is the operational test: genuinely good, interestingly bad, fluent-but-wrong. Interestingly bad is still informative — it teaches something. Fluent-but-wrong is the most dangerous category because it passes every surface filter. A practitioner without taste cannot distinguish between the two; the entire quality range collapses into one undifferentiated pile of output that passed the grammar check.
Second-order failure mode
Without taste as an internal quality signal, quality generation collapses into volume optimisation — more output, faster cycles, lower standard per unit, because no internal mechanism distinguishes signal from noise. Teams without taste-bearing members lose the capacity to curate AI-generated drafts; the model's systematic failure modes propagate into delivered work. AI output is particularly susceptible to fluent-but-wrong errors: local coherence without global structure, on-trend aesthetic mimicry that sounds like good work without being it, confident plausibility that passes the skim-read and fails the sustained engagement.
The population-level cascade is the sharper second-order. Industries that lose their taste-bearing principals — the partners, editors, art directors, senior practitioners who held the curatorial floor — do not gradually decline. They consolidate around firms that retained them, because clients with budget for premium work follow the practitioners who can still distinguish good from competent. Capital allocation drifts toward the curatorial survivors at exactly the moment when AI commoditisation makes that capacity rarer. The taste premium widens because the floor has risen while the curatorial supply has not. Firms that lose the supply lose the upper-tail work that justifies their pricing structure.
Applied here · The Bottleneck Map · §3 Chips — First-order chokepointsThe Bottleneck Map — ASML's sequential monopoly
“The €38.8 billion backlog is not a sales pipeline — it is a multi-year queue inside which the company is rationing access. Twenty-plus years of accumulated IP and the service-and-spares revenue stream on the installed base compound the monopoly.”
Read →What would change my read
Three falsifiability clauses.
The first: if the BLS OES wage differential between Art Directors and Writers and Authors compresses below 25% in two consecutive annual surveys, the market's pricing of taste as a scarce discriminant is being eroded — either AI editorial tools are absorbing the selection function, or the two roles are converging. Primary source: BLS OES, annual.17
The second: if a study (N greater than 1,000) demonstrates equivalent taste calibration in low-domain-exposure populations (under 500 hours) and high-exposure populations (over 3,000 hours), the Ericsson deliberate-practice mechanism breaks for aesthetic judgment domains and the supply constraint dissolves. Primary source: Ericsson, Krampe & Tesch-Römer (1993).16
The third: if WEF or equivalent records creative thinking and aesthetic evaluation tasks shifting from low to high AI-substitution capacity before 2030 — driven by benchmark performance reaching human expert parity — the forward-looking scarcity argument revises. Primary source: WEF Future of Jobs Report (biennial).20
Gate 2 — Judgment under uncertainty
The arithmetic
Tversky and Kahneman's "Judgment under Uncertainty: Heuristics and Biases" (Science, 1974) documented that human probability estimation systematically violates base rates through three heuristics — representativeness, availability, and anchoring-and-adjustment — with calibration errors predictable and directional: people are more confident than accurate across virtually all conditions studied.21 The default output of fast cognition without the corrective apparatus deliberate calibration supplies.
The Good Judgment Project (GJP) quantifies what that corrective apparatus is worth. Tetlock and Mellers's IARPA-funded forecasting tournament (2011–2015) found a non-normal performance distribution: a small cohort of superforecasters accumulated Brier calibration scores of 0.01, with a control-group average more than 60% worse.22 Superforecasters outperformed intelligence community analysts with access to classified information by 25–30%; year-over-year performance correlated at r=0.65 — a stability coefficient inconsistent with luck. A sub-hour calibration intervention improved Brier scores by 6–11% over control. The residual gap was explained not by IQ but by specific behaviours: aggressive use of reference classes, frequent belief updating, explicit probability notation. Chang et al. (2016) extended the finding: forecasters who first asked what is the base rate for this class of event? before constructing a narrative consistently outperformed narrative-first forecasters.23 The outside view supplies the prior that the inside view's narrative coherence would otherwise overwrite.
Gary Klein's Recognition-Primed Decision model (1993) is the necessary counterpoint.24 Klein's research on fireground commanders showed that experienced practitioners in high-feedback domains make fast, high-quality decisions through pattern-matching to prototypical situations — not by comparing options. RPD and the Tetlock findings are not contradictory: Klein's subjects operated in domains with rapid feedback loops enabling genuine pattern libraries; geopolitical forecasting lacks that feedback density, so pattern libraries built on narrative resemblance mistake familiarity for structural similarity. Judgment under uncertainty is the capacity to hold both modes: outside view to set a prior, expert pattern recognition to adjust for genuine novelty — and to know which domain you are in.
First-order failure mode
The canonical failure is overconfidence under underdetermination: the decision-maker treats narrative coherence as probabilistic evidence, ignores the reference class, anchors on the first salient framing. The error is not low information — it is the default output of System 1 without the deliberate corrective. The result is a single-point estimate stated with false precision at the moment the data support only a probability range. The decision-maker who says this will work rather than I put this at 65% has no mechanism for tracking whether their confidence is tracking their accuracy over time. The calibration gap accumulates invisibly.
The failure is also domain-transfer-resistant. A practitioner who built pattern libraries in a high-feedback domain will systematically overestimate how much that calibration transfers to low-feedback domains. The fireground commander's confidence is earned; transferred to geopolitical forecasting, the same confidence is a liability.
Second-order failure mode
Overconfident single-point estimates cause downstream capital and time misallocation in proportion to the confidence gap. Mauboussin documents the institutional version: companies projected to sustain earnings growth above 15% annually maintain it for five years only 25% of the time.25 The majority of capital allocated on inside-view narratives is misallocated by design, not by bad luck. The reputational consequence compounds: a decision-maker whose confidence persistently exceeds accuracy loses trust faster than one who is accurate-but-uncertain — the gap is observable after resolution and attributed to character.
The cascade connects to Gate 3. The practitioner who has never borne the cost of a wrong call has never updated their Brier score against reality. The superforecasters' r=0.65 stability implies a genuine skill structure built through repeated cycles of stating a probability, watching it resolve, and updating. A practitioner insulated from consequence cannot run that update cycle; their judgment stagnates at the level their starting priors supplied.
Applied here · The Falsifiability Method · §3 Structural vs cyclicalThe Falsifiability Method — structural vs cyclical
“*The math is structural; the timing is the question.* The aphorism runs through both manuscript essays. It distinguishes the diagnosis — which is true regardless of which year — from the trigger, which is unknown until it fires.”
Read →What would change my read
Three falsifiability clauses.
The first: if practitioners completing >1 hour calibration training and adopting explicit probability notation show Brier improvements of at least 6% over an untrained cohort within 90 days, the GJP-implied trainability holds. Improvements below 3% or non-persisting after training would tighten the supply constraint. Primary source: Mellers et al. (2015).22
The second: if decision-makers invoking a comparison class before constructing an inside-view narrative produce probability estimates closer to resolved frequencies by at least 30% on Brier scoring versus narrative-first estimates, the outside-view anchor is the operative mechanism. Disconfirmation would require revision of the reference-class mechanism. Primary source: Chang et al. (2016).23
The third: if a high-feedback domain practitioner (fireground commander, physician, trial lawyer with thousands of resolved cases) performs equivalently on low-feedback forecasting tasks as a trained GJP superforecaster without calibration training, the domain-transfer claim is stronger than current evidence establishes. Divergence confirms Klein's RPD as domain-bounded. Primary source: Klein (1993).24
Gate 3 — Exposure to consequence
The arithmetic
Exposure to consequence is not the same as passive experience. Ericsson, Krampe, and Tesch-Römer (1993) is the mechanistic anchor: expert performance is not a function of raw experience hours but of practice specifically designed to push current performance, with immediate accurate feedback against an objective standard.26 Among the Berlin violinists, the best performers had accumulated significantly more hours of structured, feedback-intensive solo practice — not more total playing time. Time in role without consequence-bearing feedback is naive practice; it accumulates reps without accumulating the feedback-calibrated representations that constitute expertise.
Heckman and Cunha's technology-of-skill-formation model (2006, Science; NBER 12840) closes the mechanism from the economics side.27 Skills exhibit self-productivity (acquired skills persist and multiply) and dynamic complementarity (early skill stock raises the return to later investment). The joint effect produces multiplier dynamics: the quality of early inputs sets the ceiling on later compounding. An early environment stripped of real feedback seeds a low initial stock that later investment compounds at low return. The gap is not recoverable at low cost.
Oreopoulos, von Wachter, and Heisz (NBER 12159) put a number on the early-reps effect.28 Canadian college graduates entering recession-year labour markets — who received their early-career reps in lower-quality jobs with less consequential feedback — suffered initial earnings losses of ~9% of annual earnings. The penalty halved within five years but did not disappear until roughly a decade after graduation; lower-ability graduates who could not job-hop suffered permanent losses. The mechanism is degraded early job quality and reduced employer-tier exposure — fewer consequence-bearing reps in environments where performance could be tested against market standards.
First-order failure mode
The observable failure is the twenty-year resume that reads like one year repeated twenty times. Extensive time in role; minimal evidence the incumbent was ever wrong in a measurable way and observed the consequence. Ericsson's clinical-psychology surveys document the analogue directly: practitioners do not improve with experience in domains lacking structured feedback — years of patient contact without outcome tracking does not produce greater diagnostic accuracy.26 The resume is long; the calibration is shallow.
The rep-count distinction resists self-report. The practitioner who has spent twenty years in an advisory or observer role — present for consequential decisions but not on the hook for them — has a rep-count indistinguishable from early career by this measure. They observed the consequences. They did not bear them. The feedback loop is broken at exactly the point where calibration would occur.
Second-order failure mode
When the consequence-bearing rep-count is low, judgment under uncertainty atrophies: the practitioner has not calibrated the felt sense of a bad call against the sensation of watching it land, so their internal confidence interval never tightens. Taleb's Skin in the Game names the mechanism: pathemata mathemata — learning through pain.29 Interventionistas do not learn because they are not the victims of their mistakes. The simulation literature corroborates the boundary: medical simulation shows meaningful procedural skill transfer, but the gap remains in judgment-under-ambiguity tasks, where the consequence is not did the technique work but was my read correct.30 Simulation closes the procedural rep gap, not the judgment-calibration gap — that requires real stakes on ambiguous decisions.
The cascade runs forward to the First-order layer. Founder judgment — high-variance, irreversible resource allocation under uncertainty — never develops at all in consequence-free environments, because the signal required to form the representations is absent. The consequence-bearing rep-count is not supplementary context for the First-order capabilities. It is their substrate.
Applied here · Manuscript essay · §1 (Debt math)The Math Doesn't Work — the maturity wall
“About a third of all marketable Treasury debt matures in FY2026 alone, much of it issued during 2020–2021 at coupons of one to two percent and now being refinanced at four-percent-plus. This is not a forecast. It is a mechanical event in progress.”
Read →What would change my read
Three falsifiability clauses.
The first: if graduates entering the labour market in recession years show no persistent earnings penalty relative to expansion-year cohorts (controlling for industry and education), the consequence-deprivation mechanism is weaker than the Oreopoulos natural experiment suggests. Primary source: Oreopoulos, von Wachter & Heisz, NBER 12159.28
The second: if the variance in long-run expert performance explained by deliberate practice hours converges toward the variance explained by total practice hours (including naive repetition without feedback), the Ericsson distinction loses its empirical foundation in that domain. The Macnamara-Maitra 2019 meta-analysis already finds deliberate practice explains a smaller share of variance in non-musical domains than the Berlin violin study implies. Primary source: Ericsson, Krampe & Tesch-Römer (1993).26
The third: if the technology-of-skill-formation model's dynamic complementarity parameter is empirically estimated near zero for professional judgment domains, the Heckman compounding argument does not transfer from early childhood (its empirical base) to adult professional capability development. Primary source: Heckman (2006), Science; Cunha & Heckman, NBER 12840.27
Gate 4 — Composure under pressure
The arithmetic
The body's stress response is architecturally adversarial to high-quality professional judgment. Amy Arnsten's Yale lab demonstrated that even mild acute stress triggers excessive catecholamine release in the prefrontal cortex, disconnecting the networks responsible for working memory, deliberation, and executive control while simultaneously strengthening amygdala-mediated threat responses (Nature Reviews Neuroscience, 2009).31 Performance follows an inverted-U: moderate arousal enhances performance, but the catecholamine concentrations produced by genuine high-stakes conditions tip the curve sharply downward, with dendritic changes in PFC layer II/III neurons after as little as one week of stress exposure. The mechanism is not metaphorical. The circuitry required for complex judgment is literally taken offline.
BLS OES May 2024 shows chief executives at a median annual wage of $206,420 — more than three times the all-occupation median of $67,920 — with general and operations managers at $102,950.32 These roles are defined by the requirement to deliver consequential judgment under incomplete information and stakeholder pressure. The premium rewards not domain expertise alone but the stable delivery of expertise when conditions are adversarial.
Kahneman, Sibony, and Sunstein's Noise (2021) names the decision-quality failure mode stress produces: occasion noise — the same individual producing different judgments under structurally identical conditions depending on momentary state.33 Even slight variations in mood, stress, or fatigue have surprisingly strong effects on judgment quality. The critical property of occasion noise is that it is unrecognised by the person experiencing it; the decision-maker who attributes output variance to the situation rather than to their own stress state cannot correct for a source of error they have not located. Longitudinal training data for composure development is thin;34 the Arnsten neurophysiology and the BLS wage premium are the chapter's primary anchors.
Composure is not presence (Foundation 3 names that prior condition). Composure is the high-stakes expression of a related but distinct capability — the regulated stress-response that activates when the body's cortisol cascade wants to dictate the call. A person can have strong Foundation 3 presence and still fail the composure gate when the stakes are genuinely high and the threat response fires.
First-order failure mode
The first-order failure is the flinch: the professional who is technically capable at baseline surrenders the decision to their stress response at precisely the moment it is irrecoverable. The failure is not ignorance — it is access failure under load. The technical competence exists but cannot be retrieved from behind the catecholamine curtain. Klein's fireground research found that commanders lacking sufficient pattern-recognition depth under pressure defaulted to over-deliberation or froze, even in contexts where experienced commanders moved directly to execution in under 30 seconds.35 The flinch takes different forms — the executive who defers a strategic call until the moment for making it has passed, the clinician who orders more tests when the presentation demands a decision, the negotiator who gives the concession before the other side has even asked. Stress is managing the human rather than the human managing the stress.
Second-order failure mode
The second-order is capability collapse at system level: an individual who performs well in low-stakes settings fails to transfer that competence upward to the roles where it compounds most. Founder judgment, complex enterprise sales, medical diagnosis under time pressure, crisis management — all require ground-state skill plus composure as a gate, not as a bonus. Duckworth's grit research is instructive by negative example: grit (sustained effort toward long-term goals) predicted success across West Point retention, Ivy League GPA, and Spelling Bee ranking, accounting for variance beyond IQ and conscientiousness.36 But grit is a slow-burn persistence capability; composure is a real-time regulation capability. The gap is where second-order failures occur: high-grit, high-skill individuals who lack the composure gate wash out at inflection points not because they stopped trying but because the stress response overrode their judgment at the moment the call was irreversible.
The organisational-level cascade is the unobvious move. When senior leadership lacks the composure gate, firms make their worst-quality decisions at moments of maximum visibility and irreversibility — earnings-call commentary that crystallises a wrong narrative the analyst desk amplifies, M&A timing made under acquirer-fatigue rather than calibrated assessment, crisis-response statements that fix the wrong interpretation in the public record before the facts have resolved. The composure deficit does not scale linearly; it concentrates in the decisions most exposed to scrutiny, which are also the decisions most consequential for the firm's compounding trajectory. Composure functions as a bottleneck rather than an amplifier in the capability stack: when present, every other capability operates at full fidelity under pressure; when absent, the entire stack is limited by the worst performance under the worst conditions — which are exactly the conditions high-stakes roles are defined by.
Applied here · Signal · Cap-to-GDP · What would change my readUS Equity Market Cap / GDP — falsifiability statement
“A return to the 175% band — the prior 2000 peak — would require either a ~30% index drawdown or sustained nominal GDP growth meaningfully above current trend. The historical resolution mechanism for cap/GDP this extreme is the former, not the latter.”
Read →What would change my read
Three falsifiability clauses.
The first: if a professional can articulate their own physiological stress cues (heart rate elevation, attention narrowing, respiration rate) and name a pre-committed decision protocol for each high-stakes scenario type they regularly face, composure capacity is functional. The protocol must be pre-encoded before the stress event, not constructed during it — Klein's RPD model: experts succeed under pressure not by deliberating faster but by pattern-matching to pre-built prototypes. Primary source: Klein (1993).35
The second: if a decision-maker spontaneously revises a position mid-meeting when presented with disconfirming evidence — without defensive escalation, in real time, under evaluative scrutiny — the composure threshold for confident humility is met. If revision only occurs after the meeting when social pressure has lifted, composure was absent at the moment of consequence. Grant's Think Again (2021) defines confident humility as revision-openness under evaluative scrutiny.37
The third: if occasion noise — within-person judgment variance across structurally identical decision scenarios presented one week apart — falls below 15%, composure substrate is present. Above 30%, stress-reactive noise dominates judgment quality. Self-report is unreliable proxy; structured re-presentation is required to measure. Primary source: Kahneman, Sibony & Sunstein, Noise (2021).33
Gate 5 — Accumulated body of work
The arithmetic
Michael Spence's "Job Market Signaling" (QJE, 1973) identified the foundational information problem: the employer is not sure of an individual's productive capabilities at the time of hire.38 A portfolio of demonstrated output is the closest available resolution — accumulated observable prior outcomes rather than a proxy for unobservable ability. The structural property: the cost of building a credible portfolio is differentially high for those who do not yet have the underlying productive capacity to fill it. Fabrication is expensive in proportion to the gap between signal and underlying capability. This is why the signal works. It is also why it is time-gated.
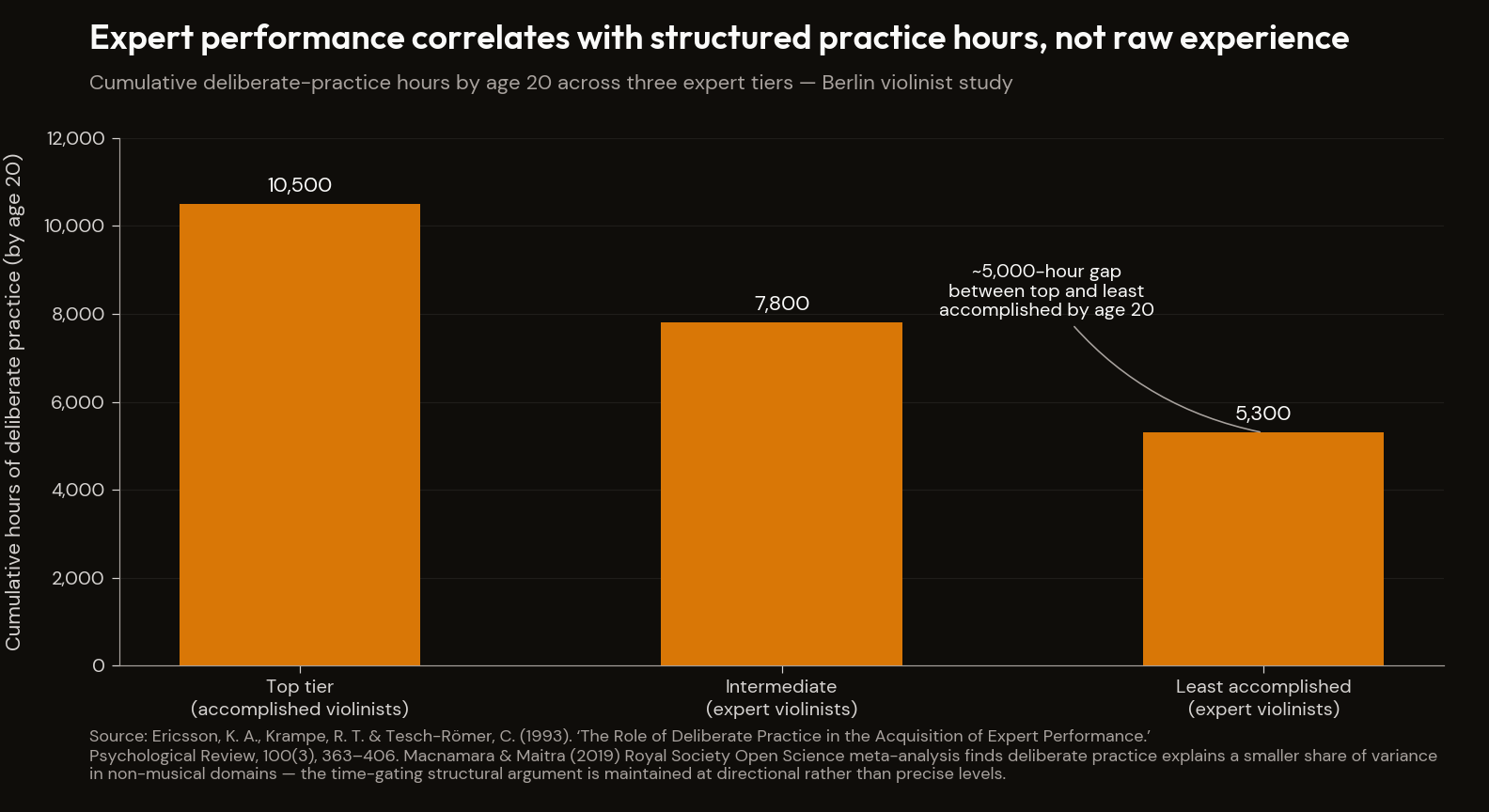
Ericsson, Krampe, and Tesch-Römer (1993) supplies the compound-returns substrate.39 By age 20, the most accomplished Berlin violinists had accumulated over 10,000 hours of deliberate practice — ~2,500 hours more than the intermediate group, ~5,000 more than the least accomplished. "Many characteristics once believed to reflect innate talent are actually the result of intense practice extended for a minimum of ten years." The 10,000-hour figure has been contested — Macnamara and Maitra (2019) found deliberate practice explains a smaller share of variance in non-musical domains, and the chapter's reach into professional judgment should be held at directional rather than precise.40 The structural argument holds: portfolio quality is a function of how much embedded, corrected experience underlies each artefact.
Robert Topel's "Specific Capital, Mobility, and Wages" (JPE, 1991) estimates that ten years of job-specific seniority raises the wage of the typical male worker by over 25% — accumulated job-specific human capital, not general experience.41 In high-compensation professional domains, the gap is larger: BigLaw partnership now requires a median of 8–10 years from first-year associate, with 31% of 2021 ALM New Partners survey respondents requiring 11–15 years.42 The partnership track has lengthened by more than 61% since 2012. The demonstrated-work bar is rising, not compressing, as AI tools make surface-level output cheaper.
First-order failure mode
The observable failure is high-volume output without compounding portfolio effect: frequent publication or deliverable production that does not accumulate into a coherent, referenceable body because each piece is context-free, unlinked to prior work, or inconsistent in domain. A related variant: impressive recent work with no archive — strong output that cannot be situated in a track record because there is nothing behind it to contextualise its quality or durability. Each new piece starts audience acquisition from zero rather than inheriting the credibility of what preceded it. The output volume is present. The body is not.
Second-order failure mode
Without a compounding archive, the capability has no legible history of prior bets and outcomes that would allow counterparties to independently assess reasoning quality over time. Spence's signaling model requires that a signal be observable by the receiver, costly to produce, and differentially costly for senders who lack the underlying quality it signals. A portfolio that cannot be read forward from prior work is not a signal in Spence's sense. It is an assertion. Assertions without prior-outcome track records require the counterparty to take capability on faith — which high-stakes allocators (capital, institutional clients, strategic partners) are structurally disinclined to do.
Accumulated body of work is the human analogue of accumulated process knowledge in capital-intensive industries. The peptide CMO bottleneck in GLP-1 manufacturing is the structural parallel: capacity to produce is a function of process knowledge accumulated over years of validated runs, not investment in physical assets alone. New capital can build the facility but cannot buy the process understanding that makes it capable of producing at specification. Capital can fund a year of intensive output; it cannot buy the archive that makes new output legible as part of a coherent judgment history.
Applied here · The Bottleneck Map · §4 Eldercare — Second-order chokepointsThe Bottleneck Map — peptide CMO capacity gate
“Capacity gating at the peptide CMO layer determines how fast the Novo/Lilly duopoly can grow GLP-1 volume; until the new capacity ramps, manufacturing constraints — not patent expiry — set the supply curve.”
Read →What would change my read
Three falsifiability clauses.
The first: if Topel's 25% ten-year job-specific wage premium is not replicated in more recent longitudinal wage data — either because job-specific capital depreciates faster post-2010 or because general skills have become more portable — the wage-tenure anchor weakens. The Topel estimate covers male workers through the 1980s; applicability to professional knowledge work in 2026 requires verification against contemporary data. Primary source: Topel (1991); NBER 3294.41
The second: if AI-assisted portfolio production allows a practitioner to compress ten years of demonstrated output into three — work at volume and quality equivalent to a decade's accumulation in less than a quarter of the time, with evidence of coherent judgment throughout — the time-gating argument requires fundamental revision. The threshold is not that AI makes more work possible; it is that AI makes genuinely calibrated work possible without the underlying rep-count. Primary source: Ericsson, Krampe & Tesch-Römer (1993).39
The third: if BigLaw partnership timelines compress below six years for the median (eight years 75th percentile) in response to AI-assisted associate work product, the demonstrated-work bar is falling in at least one consequential professional domain. The partnership track lengthening since 2012 runs the opposite direction; a reversal would be meaningful signal. Primary source: ALM New Partners Survey 2021.42
The Gates layer ends here. What these five capabilities share is a supply constraint the Foundation layer does not impose: they cannot be reached from outside the consequence-bearing path. The practitioner who has not built taste through saturation, updated calibration through resolved decisions that cost something, remained functional under stress, or accumulated a legible history of prior bets cannot acquire these capabilities through instruction, simulation, or effort alone. The Foundation provides the substrate. The Gates require the reps.
First-order capabilities — the visible layer
Three capabilities occupy the outermost layer: quality generation, complex sales and trust at high stakes, and founder judgment. They are the capabilities the labour market talks about because they are economically legible — they have prices attached, compensation structures, a clear mechanism connecting performance to reward. They are also the capabilities most commonly reached for without the layers below being built.
The document's claim about this layer is structural. Each premium is real. The claim is that each premium is durable only when the Gates beneath are actually built: quality generation without taste collapses into volume; complex sales without composure fails exactly when the stakes are highest; founder judgment without exposure to consequence is confidence without calibration. The First-order capabilities are the visible surface. The load-bearing structure is below them.
| Capability | Supply constraint | Failure mode |
|---|---|---|
| FO1 — Quality generation | Taste-bearing principals + accumulated taste calibration | Output indistinguishable from the AI floor — priced at floor |
| FO2 — Complex sales & trust at high stakes | Composure + accumulated client relationships | The deal stalls at the trust gate |
| FO3 — Founder judgment | Exposure to consequence + accumulated body of work | Allocating on legible signals; discounting first-person consequence |
First-order 1 — Quality generation
The arithmetic
BLS Occupational Employment and Wage Statistics for May 2024 show management occupations at a 90th-percentile annual wage of roughly $231,620 against a median of $116,880 — a 1.98x ratio, the top decile earning approximately 98% more than the median in the same broad occupational family.43 Autor, Levy, and Murnane's "The Skill Content of Recent Technological Change" (QJE, 2003) established the mechanism: computerisation substitutes for workers in routine cognitive tasks while complementing workers in non-routine problem-solving, and "wage dispersion in non-routine occupations unambiguously rises" as substitution advances.44 Autor's 2014 Science paper documented the result over time: the US 90/10 earnings ratio grew by more than 100 percentage points between 1980 and 2011, with rising returns to cognitive ability explaining 60–70% of the rise in US wage dispersion.45
Generative AI accelerates this dynamic and extends it into categories previously considered automation-resistant. McKinsey Global Institute (June 2023) estimates 60–70% of employee time now technically automatable — up from roughly 50% before generative AI — with management and talent-development automation rising from 16% in 2017 to 49% in 2023.46 When AI raises the floor by enabling median practitioners to produce outputs that previously required top-quartile skill, the remaining premium accrues entirely to what the AI cannot replicate. PwC's 2025 Global AI Jobs Barometer puts numbers on the emerging polarisation: roles requiring demonstrated AI skills carry a 56% wage premium over comparable non-AI roles, with productivity growth quadrupling in the most AI-exposed sectors.47
First-order failure mode
The observable failure is high-volume, competent-but-undifferentiated output — work that is correct, thorough, and indistinguishable from what the AI could have generated without the practitioner. Because AI raises the floor, the floor becomes the reference price. Output that cannot be distinguished from it gets priced at it. The failure does not announce through a single bad piece of work; it announces through a pricing conversation in which the counterparty cannot name what the practitioner uniquely provides.
Second-order failure mode
The pricing cascade is the second-order move. When a practitioner's output cannot be distinguished from the AI floor, the counterparty has no analytical mechanism by which to pay more than the floor — every pitch becomes a comparison against an AI-generated alternative the buyer can produce themselves at near-zero marginal cost. The practitioner's audience-compound rate drops toward zero because the work carries no specific signal worth recommending. Each new piece launches into the same effective market as the previous one, priced at the same compressed level.
The population-level cascade runs at the firm scale. Organisations whose senior practitioners cannot generate above-the-AI-floor output do not gradually decline. They consolidate downward: the top-of-distribution clients migrate to firms whose principals can still produce work the AI cannot, while the median-tier work compresses around an AI-equivalent price point. The widening happens from below, not above — as AI makes competent-looking output cheap and abundant, the upper tail becomes more distinguishable, not less. Quality generation is the First-order capability for capturing that tail. The supply constraint is Gate 1 — taste — the internal mechanism that distinguishes genuinely good from fluent-but-wrong. Firms that lose the supply lose the upper-tail work that justifies their pricing structure; firms that retained it absorb the share. The market premium on quality-generating roles is the current snapshot of that redistribution.
Applied here · Manuscript essay · §4 (Entitlement math)The Math Doesn't Work — the unresolved Medicare HI gap
“Medicare HI (Part A, hospital insurance): Trustees say 2033. CBO says 2040, a seven-year methodological gap on Medicare cost-growth assumptions that I do not think gets resolved in the optimistic direction.”
Read →What would change my read
Three falsifiability clauses.
The first: if the BLS 90th/50th wage ratio for knowledge-intensive occupational groups does not widen between the May 2024 and May 2026 OEWS releases relative to AI-exposure-indexed occupations, the widening-premium hypothesis is falsified and an alternative "AI commoditises the frontier too" reading gains traction. Primary source: BLS OEWS, published annually.43
The second: if McKinsey's automation-potential estimate for management activities (49% in 2023) rises toward 70% or higher by 2026 without a corresponding rise in top-quartile compensation, automation is compressing even frontier-quality outputs — the correct model is universal compression, not floor-lift. Primary source: McKinsey MGI, June 2023.46
The third: if the PwC AI-skills wage premium (56% in 2025) plateaus or narrows by the 2026 Global AI Jobs Barometer release, the market has fully priced AI-skill acquisition and a different differentiator must be named. Primary source: PwC Global AI Jobs Barometer 2025.47
First-order 2 — Complex sales & trust at high stakes
The arithmetic
BLS OES May 2024 puts the median annual wage for Securities, Commodities, and Financial Services Sales Agents (SOC 41-3031) at $78,140, with the 90th percentile exceeding $215,210.48 Retail salespersons (SOC 41-2031) earned a median of approximately $33,000 in the same period. The spread at the top-decile level — where senior relationship managers sit — runs to a 4–6x multiple over the base sales labour market. Senior investment banking managing directors at boutique advisory firms averaged total packages near $494,000 in 2024, driven by variable pay tracking relationship tenure, deal completion, and repeat mandates. The gap is not a credential premium. It is a trust-delivery premium. The buyer at a $50 million private placement is not purchasing a capability demonstration — they are underwriting a judgment call on whether this person will still be accountable to them in year three.
Moorman, Deshpandé, and Zaltman (1993, Journal of Marketing, 57:81–101) identified interpersonal trust factors — perceived integrity, expertise, confidentiality, and congeniality — as the most predictive variables of sustained advisory relationships, above all organisational or project factors, in a sample of 779 user-researcher dyads.49 Trust is overwhelmingly constituted in the individual relationship, not in the brand or artefact. Weitz and Bradford (1999, JAMS, 27:241–254) documented the shift in personal selling from influencing buyer behaviour toward managing the ongoing conflict inherent in buyer-seller relationships — a shift that requires trust as its operating currency.50 McKinsey (2023) identified roughly one-fifth of sales-team functions as automatable, concentrated in prospecting, lead qualification, and documentation — the transactional substrate.51 The residual: the relationship layer, which becomes a higher fraction of what the human is paid to do as the transactional substrate automates.
First-order failure mode
The deal stalls at the trust gate. A technically competent pitch — accurate financials, well-structured term sheet — fails to close because the counterparty is not yet confident that the person across the table will manage the relationship after the wire clears. The artefact passes; the person does not. The failure is not visible in the pitch. It is visible in the pattern of near-closes that do not resolve.
Second-order failure mode
Organisations that mistake the trust deficit for a product or pricing problem build a thicker pitch book for a meeting that needed a different kind of presence. The senior relationship manager who would have carried the deal remains underdeployed; the junior who cannot carry it is over-promoted into the room; the firm loses not one deal but the compounding option value of the relationship over a multi-year mandate cycle. Composure is the Gate that feeds this capability most directly — the trust relationship fails exactly when the client is under pressure and the relationship is tested by an adverse event. Composure is not a bonus in those moments. It is the gate.
Applied here · Manuscript essay · The End of the Bull Run · OpenerThe End of the Bull Run — the refusal of dates
“I have held some version of the bear position on US equities since 2021. I have been wrong on timing every year since. I am not going to call the date. I am going to describe the regime, set out the math, and let the reader decide what posture is appropriate to it.”
Read →What would change my read
Three falsifiability clauses.
The first: if the 90th-percentile wage for SOC 41-3031 declines in real terms relative to the national sales median over 2024–2029 as AI tools for prospecting and pitch construction diffuse, AI is substituting into the trust layer, not just the transactional substrate — commoditisation of deal preparation compresses total compensation. Primary source: BLS OES annual release.48
The second: if average enterprise software deal cycles for contracts above $500,000 ACV shorten by more than 20% between 2024 and 2028, the trust assembly problem is being partially solved by AI tools. Current baseline: 6–18 months for true enterprise deals, up 22% since 2022. Primary source: B2B sales cycle industry benchmarks.52
The third: if a large-scale study demonstrates that interpersonal trust — Moorman et al.'s integrity, expertise, confidentiality, congeniality cluster — is as well constituted in AI-mediated advisory relationships as in named-person relationships among institutional buyers, the moat narrows to a subset of extreme-stakes transactions. The 2026 Edelman data show that familiarity with AI tools shifts sceptics toward trust by 26–46 percentage points; threshold parity among HNWI segments would be meaningful signal. Primary source: Moorman, Deshpandé & Zaltman (1993).49
First-order 3 — Founder judgment
The arithmetic
Venture-capital outcome distributions are structurally skewed: within a typical fund of 20–30 portfolio companies, 1–3 investments generate 50–80% of total fund returns; the bottom half contributes roughly 11% of aggregate value.53 The Kauffman Foundation's 2012 study of its own 20-year, nearly-100-fund portfolio found that 62 out of 100 venture funds failed to beat a public-market equivalent after fees, and only 20 beat it by more than 3 percentage points annually.54 Formation judgment — what to attempt, when, with what resources, by whom — absorbs a disproportionate share of the variance before any operational management begins. Execution matters. Formation judgment determines the distribution in which execution is operating.
Noam Wasserman's peer-reviewed study of 3,600 startups found that fewer than 25% of founder-CEOs lead their companies to IPO, and four out of five are ousted from the CEO role.55 His Organization Science (2003) paper identified the structural paradox: founders are removed most frequently not when companies fail but when companies perform well — outside investors replace them with a professional manager suited to the next stage. Founding judgment and ongoing management judgment are separable capability sets at different time horizons. Whether founding intuition is reliable or noise depends on the environment. Kahneman and Klein (2009, American Psychologist) establish that skilled intuition is reliable only when the environment displays sufficient regularity and the decision-maker has had adequate opportunity to learn that structure through feedback.56 New-venture formation is a wicked environment: feedback is delayed, infrequent, and confounded by luck. Founder intuition is unreliable absent deliberate prior exposure to consequence and accumulated pattern — which is precisely why Gates 3 and 5 feed into this capability rather than substituting for it. Founder judgment is the upstream Gates' largest downstream consumer.
First-order failure mode
The observable failure is allocating time and capital toward a venture on legible signals — traction metrics, peer enthusiasm, market-size estimates — while discounting harder-to-articulate evidence embedded in direct operator experience. Because founding environments are wicked, founders over-anchor on what can be documented and shown to others rather than on pattern-recognition built from personally bearing consequences across prior cycles. The result is ventures launched at the wrong stage, in the wrong market — not because the arithmetic was wrong, but because the self-assessment preceding it was not grounded in first-person consequence. The failure is invisible at launch. It resolves at stall.
Second-order failure mode
The formation-stage error compounds: each hire and each round of financing raises the social and financial switching cost of updating the original judgment. Early capital deploys against a decision never genuinely stress-tested against the founder's actual comparative advantage; the team optimises execution on a poorly-chosen direction; the company stalls at a plateau that signals founding-judgment failure, not operational failure. Wasserman's paradox inverts — here it is underperformance, not success, that triggers board-driven succession, and the years consumed are not recoverable. The Gates are not decorative. The consequence-bearing rep-count Gate 3 describes is the substrate from which pattern libraries form in wicked environments — the only mechanism Kahneman and Klein identify as capable of making founder intuition reliable rather than merely confident.
Applied here · The Falsifiability Method · §4b Regime + triggers, not datesThe Falsifiability Method — regime + triggers, not dates
“describe the regime; name the triggers; refuse the dates. Long-form theses are about describing structural configurations and the events that would shift them. They are not about predicting when the events will fire.”
Read →What would change my read
Three falsifiability clauses.
The first: if founder-led ventures surviving past Series A with the original founder as CEO do not outperform professionally-managed substitutions on five-year revenue CAGR across a large-sample, multi-sector study, founding judgment at formation does not have the compound value the Wasserman data imply and the separability argument weakens. Primary source: Wasserman, Organization Science, 14(2), 2003.57
The second: if founders with documented prior venture consequence — a previous company reaching revenue before failing, or direct domain operating experience — show no statistically significant lower Series A failure rate than first-timers after controlling for capital access, the Kahneman-Klein feedback-loop mechanism does not transfer to founding environments and the Gate 3 dependency does not hold. Primary source: Kahneman & Klein (2009), American Psychologist.56
The third: if Cambridge Associates or Kauffman Foundation data show the power-law return distribution in venture funds compressing — more companies contributing to returns, less skew from the top 1–3 — the formation-judgment argument weakens as an explanation of variance and operational execution explains more. Primary source: Kauffman Foundation (2012).54
The stack, read whole
The three layers have different supply constraints.
Foundation is supply-constrained by atrophy and adversarial environment, not by scarcity of the capability itself. Critical thinking, AI direction literacy, and presence are trainable under the right conditions but actively degraded by structural forces (information hostility, notification architecture, engineered switching). The environment degrades them in the population not building them deliberately, making deliberate building a rarer act than it looks from outside.
First-order capabilities are supply-constrained by instruction and accumulated deployment. Quality generation, complex sales, and founder judgment can all be learned — the arithmetic of the premium can be understood, the mechanisms can be studied, the patterns transferred. They require effort and time, but the path is legible and the milestones are visible.
The Gates layer is where actual scarcity lives. Taste, judgment under uncertainty, exposure to consequence, composure under pressure, and accumulated body of work are supply-constrained by lived consequence at scale — rep count where the practitioner was on the hook. The labour market selects for this exactly because it cannot be faked in an interview. An interviewer can probe with a short sequence: What was the worst call you made that cost you money or a client? What did you learn? What would you do differently? The practitioner who answers with hypotheticals and attributions has the answer; so does the interviewer. The Gates resist forgery because they leave observable residue in how a practitioner describes their own wrong calls.
Of the five Gates, two are time-gated by definition. Exposure to consequence requires that the feedback resolved — the practitioner watched the downstream effect of a decision they could not un-make. Accumulated body of work cannot be compressed without degrading the signal. Not coincidentally, these two Gates are the substrate for the two First-order capabilities with the highest compensation premiums: founder judgment and complex sales at high stakes.
The labour market's pricing of these distinctions is observable in the BLS wage data the chapters above cite. Roles that require selection over production, and roles that require trust and composure over transactional execution, carry persistent premiums:
| Role (BLS SOC) | Median | 90th percentile | Premium / ratio | Cited in |
|---|---|---|---|---|
| Art Directors (27-1011) | $111,040 | — | 54% over Writers & Authors | Gate 1 — Taste |
| Writers & Authors (27-3043) | $72,270 | — | (reference) | Gate 1 — Taste |
| Chief Executives (11-1011) | $206,420 | — | 3.07× all-occupation median | Gate 4 — Composure |
| All occupations (BLS national) | $67,920 | — | (reference) | Gate 4 — Composure |
| Securities/Commodities Sales (41-3031) | $78,140 | $215,210+ | 90th = 2.75× median | First-order 2 — Complex sales |
| Retail Salespersons (41-2031) | ~$33,000 | — | (reference) | First-order 2 — Complex sales |
| Management Occupations (broad) | $116,880 | $231,620 | 90/50 ratio 1.98× | First-order 1 — Quality generation |
Source: BLS Occupational Employment and Wage Statistics, May 2024.
Foundation capabilities are becoming more supply-constrained, not less, as the information environment becomes more adversarially engineered. The Reuters Institute data describes a population where news avoidance is at a record high and discernment-relevant worry persists at majority levels. The population that exits the problem rather than solving it is growing. The asymmetry widens.
This document does not say prepare. This is the Method's discipline applied to the human-capital question: describe the regime, name what would change the read, let the reader decide what posture is appropriate. The posture depends on where the reader is in the stack, what layer is missing, and what constraints bind them — questions only the reader can answer. The document is not a decision tree. It is an audit framework. The reader runs the audit.
A worked example — the senior associate considering partner
End-to-end demonstration of the audit on a single practitioner. The case is a senior associate at a Big Four audit firm — six to eight years in, considering whether to drive toward partnership or exit. The eleven-capability audit applied in order, against one practitioner.
Foundation 1 — Discernment. Audit training drilled this. The what's not in the books question is the operational form of discernment in this domain. Present at functional depth.
Foundation 2 — AI direction. This is where the audit reveals the first gap. The associate has been issued the firm's AI tools and uses them for sample-selection, working-paper drafting, and analytical procedures. They have not internalised the failure-mode map — sycophancy under partner pushback, hallucination on transaction details under nominal-name confusion, calibration collapse on lower-population disclosures. The failure mode is invisible because each engagement passes firm review. It will surface when a PCAOB or FRC inspection drills into an AI-influenced workpaper trail. Present in surface form; not in structural literacy.
Foundation 3 — Presence. The associate has not put down their phone during a client meeting in three years. They check Slack during conversation with their team. They cannot sustain twenty minutes of single-task focus on a complex disclosure without self-interrupting. Foundation 3 deficit: severe. The Gates that require sustained attention to load are being undermined at the substrate level.
Gate 1 — Taste. Years of exposure to varied disclosures, audit findings, and management-letter recommendations have built the curatorial capacity. The associate can read a draft management report and locate the three sentences that should be cut, the one that should be added, and the structure that doesn't quite track. Present.
Gate 2 — Judgment under uncertainty. Has the associate explicitly named their probability estimate before a partner-disputed materiality call? Have they written down what would resolve the dispute and tracked the resolution? Almost always no — the firm's framing privileges defensible-conclusion language over calibrated-probability notation. The Gate is approached, not crossed.
Gate 3 — Exposure to consequence. The Big Four structure absorbs consequence at the partner level. The associate has been on the hook for individual workpaper conclusions but has not borne the cost of a wrong call in a personal-liability or client-loss outcome. Real reps on procedural judgment; the higher-order calibration that comes from bearing consequence directly remains structurally undeveloped.
Gate 4 — Composure. Has the associate ever delivered a materially disagreeable finding to a CFO who pushed back hard in real time? Has the stress response stayed below the threshold where it would have dictated a softening of the conclusion? In some cases yes, in others no — and the cases where the answer is no are not always recognised as such at the time. In active development; not consolidated.
Gate 5 — Body of work. Six to eight years of partner-supervised workpaper output and named engagement contributions. Internally legible at the firm level. Externally — for any career move outside the firm — limited to the standard credential. The portfolio exists in form, not in legible-to-external-counterparties depth. Present internally; undeveloped externally.
First-order 1 — Quality generation. The associate produces audit deliverables at firm-standard quality consistently. They generate above-the-AI-floor work in the areas where their accumulated taste and judgment are operative — particularly disclosure drafting and risk-paragraph language. They do not yet have the demonstrated track record of generating frontier-quality output independent of firm review. Developed in the firm-supported case; undeveloped in the independent case.
First-order 2 — Complex sales. Limited direct exposure. The associate has accompanied partners to client meetings but has not led an audit committee presentation, has not closed a new engagement, has not been the trusted relationship the audit committee asks to keep on next year's mandate. Nascent.
First-order 3 — Founder judgment. Has the associate ever made a high-variance, irreversible resource allocation under genuine uncertainty? In their personal life perhaps; in their professional life almost certainly not — the Big Four operating model is designed to insulate associates from formation-stage decisions. Structurally undeveloped. Gate 3 is the supplying substrate, and that substrate is itself only partially-built.
The synthesis. Foundation layer almost intact, with the Foundation 2 and Foundation 3 gaps named. Most Upstream Gates approached but not consolidated: Gate 2's explicit-notation discipline, Gate 3's consequence-bearing reps, Gate 4's hostile-client composure. One First-order capability developed within firm review (Quality generation) and two essentially undeveloped (Complex sales, Founder judgment).
The partner-track decision becomes legible against the audit. Driving toward partnership inside the firm continues to develop Gates 3, 4, and 5 along the existing trajectory — slowly, with consequence partially absorbed. It does not develop First-order 2 or 3 substantially, because the Big Four operating model gates those capabilities behind specific roles (relationship-partner, practice-lead) reached late in the partner track if at all. An exit to a smaller firm, an independent practice, or a startup CFO role accelerates the consequence-bearing reps Gates 3 and 4 require — at the cost of the institutional buffer that has been compensating for the Foundation 2 and Foundation 3 gaps.
The audit does not produce the partner-vs-exit decision. It produces the map against which the decision becomes legible: where the stack is built, where it is gated, and what each path develops next. That is the method's output.
The Scenario Playbooks will apply the Method to conditional posture frameworks — what to do if the thesis resolves in Direction A versus Direction B. The Capability Stack describes the inventory. The Playbooks will describe the branching postures. That is the division of labour between the two documents, and it is the same division the Method makes between structural description and decision-trigger.
Footnotes
-
Reuters Institute Digital News Report 2025. https://reutersinstitute.politics.ox.ac.uk/digital-news-report/2025/dnr-executive-summary ↩ ↩2
-
Pennycook et al. 2024 PNAS meta-analysis, 31 experiments, N=11,561. https://www.pnas.org/doi/10.1073/pnas.2409329121 ↩ ↩2
-
Pew Research Center, August 2025, N=5,153. https://www.pewresearch.org/short-reads/2025/10/29/many-americans-say-they-often-come-across-inaccurate-news-and-have-a-hard-time-knowing-whats-true/ ↩ ↩2
-
List, Ramirez et al., PNAS Nexus 2024, N=2,235. https://academic.oup.com/pnasnexus/article/3/10/pgae361/7821167 ↩
-
2026 Edelman Trust Barometer, 34,000 respondents, 28 countries. https://www.edelman.com/trust/2026/trust-barometer ↩ ↩2
-
Hendrycks et al., MMLU, 2021. arXiv:2009.03300. https://arxiv.org/abs/2009.03300 ↩
-
Stanford CRFM, HELM evaluation. arXiv:2211.09110. https://arxiv.org/abs/2211.09110 ↩
-
Sharma et al. (2023), ICLR 2024. arXiv:2310.13548. https://arxiv.org/abs/2310.13548 ↩
-
WEF Future of Jobs Report 2025. https://www.weforum.org/publications/the-future-of-jobs-report-2025/ ↩
-
Acemoglu & Restrepo (2019), AEA Journal of Economic Perspectives 33(2). https://www.aeaweb.org/articles?id=10.1257/jep.33.2.3 ↩
-
González, M. & Mark, G. (2004). "Constant, Constant, Multi-tasking Craziness: Managing Multiple Working Spheres." ACM CHI 2004. https://dl.acm.org/doi/10.1145/985692.985707 [Note: the research brief flags that the DOI links in search results for this paper route inconsistently; the 2023 book Attention Span is the cleanest single source for the full longitudinal arc.] ↩
-
Pew Research Center, January 2024. "Americans' Use of Mobile Technology and Home Broadband." https://www.pewresearch.org/internet/2024/01/31/americans-use-of-mobile-technology-and-home-broadband/ ↩
-
Common Sense Media (2023). Constant Companion: A Week in the Life of a Young Person's Smartphone Use. https://www.commonsensemedia.org/research/constant-companion-a-week-in-the-life-of-a-young-persons-smartphone-use [Note: sample is 203 young people aged 11–17; adult figures from Pew are expressed as frequency category ("almost constantly") rather than discrete check counts — do not conflate the two samples.] ↩
-
Turkle, S. (2015). Reclaiming Conversation: The Power of Talk in a Digital Age. Penguin Press. The 89%/82% figures are from this volume. The underlying controlled study on phone-on-table effects is Przybylski & Weinstein (2012), Journal of Social and Personal Relationships — verify independently before additional citation. ↩ ↩2
-
Mark, G. (2023). Attention Span: A Groundbreaking Way to Restore Balance, Happiness and Productivity. Hanover Square Press. https://gloriamark.com/attention-span/ ↩ ↩2
-
Ericsson, K.A., Krampe, R.T. & Tesch-Römer, C. (1993). "The Role of Deliberate Practice in the Acquisition of Expert Performance." Psychological Review, 100(3), 363–406. https://psycnet.apa.org/record/1993-40718-001 ↩ ↩2
-
BLS OES May 2024. Art Directors (SOC 27-1011): https://www.bls.gov/oes/current/oes271011.htm; Writers and Authors (SOC 27-3043): https://www.bls.gov/ooh/media-and-communication/writers-and-authors.htm ↩ ↩2
-
The BLS differential is a directional proxy, not a clean measure of taste premium. Art Directors differ from Writers and Authors on many dimensions beyond taste calibration — scope of role, management component, industry mix. The 54% differential cannot be cleanly attributed to taste alone. ↩
-
Bourdieu, P. (1984). Distinction: A Social Critique of the Judgement of Taste. Harvard University Press. The habitus concept describes aesthetic judgment as embodied through sustained field immersion rather than transmitted by instruction — primarily a sociological and class-analytic argument; its application to individual skill acquisition requires a theoretical bridge the literature does not fully close. ↩
-
WEF Future of Jobs Report 2025. https://www.weforum.org/publications/the-future-of-jobs-report-2025/digest/ ↩ ↩2
-
Tversky, A. & Kahneman, D. (1974). "Judgment under Uncertainty: Heuristics and Biases." Science, 185(4157), 1124–1131. https://www.science.org/doi/10.1126/science.185.4157.1124 ↩
-
Mellers, B. et al. (2015). "The Psychology of Intelligence Analysis: Drivers of Prediction Accuracy in World Politics." Perspectives on Psychological Science, 10(3), 267–281. https://faculty.wharton.upenn.edu/wp-content/uploads/2015/07/2015---superforecasters.pdf ↩ ↩2
-
Chang, W. et al. (2016). "Developing expert political judgment: The impact of training and practice on judgmental accuracy in geopolitical forecasting tournaments." Judgment and Decision Making. The reference-class-first mechanism is established in the GJP literature broadly; specific Brier-score deltas not cited from primary text. ↩ ↩2
-
Klein, G.A. (1993). "A Recognition-Primed Decision (RPD) Model of Rapid Decision Making." Decision Making in Action: Models and Methods. https://psycnet.apa.org/record/1993-97634-006 ↩ ↩2
-
Mauboussin, M.J. The Base Rate Book, Credit Suisse Global Financial Strategies, 2016. Practitioner document rather than peer-reviewed journal; treat as corroborating illustration rather than primary empirical anchor. ↩
-
Ericsson, K.A., Krampe, R.T. & Tesch-Römer, C. (1993). Psychological Review, 100(3), 363–406. https://psycnet.apa.org/record/1993-40718-001 ↩ ↩2 ↩3
-
Heckman, J.J. (2006). "Skill Formation and the Economics of Investing in Disadvantaged Children." Science, 312(5782). https://www.science.org/doi/10.1126/science.1128898; Cunha, F. & Heckman, J.J., NBER Working Paper 12840. https://www.nber.org/papers/w12840 ↩ ↩2
-
Oreopoulos, P., von Wachter, T. & Heisz, A. NBER Working Paper 12159. https://www.nber.org/papers/w12159 ↩ ↩2
-
Taleb, N.N. (2018). Skin in the Game: Hidden Asymmetries in Daily Life. Random House. The pathemata mathemata formulation is the mechanism label for consequence-deprivation; it carries no quantitative substrate of its own. ↩
-
Medical simulation literature shows procedural skill transfer on intubation and surgical technique tasks. The boundary condition — simulation closes the procedural rep gap, not the judgment-calibration gap — is drawn from the research brief's assessment of the simulation counter-evidence. ↩
-
Arnsten, A.F.T. (2009). "Stress signalling pathways that impair prefrontal cortex structure and function." Nature Reviews Neuroscience, 10, 410–422. https://pmc.ncbi.nlm.nih.gov/articles/PMC2907136/ ↩
-
BLS OES May 2024. Chief Executives (SOC 11-1011): https://www.bls.gov/oes/current/oes111011.htm; all-occupation median: BLS OES national estimates. ↩
-
Kahneman, D., Sibony, O. & Sunstein, C.R. (2021). Noise: A Flaw in Human Judgment. Little, Brown Spark. ↩ ↩2
-
Longitudinal training outcome data for composure development is weak. A 2025 systematic review of 32 empirical studies on naturalistic decision-making in high-risk professions (healthcare, aviation, military, fire/rescue) explicitly notes "insufficient evidence connecting specific strategies to outcomes" and "limited understanding of stress coping strategies." (https://pmc.ncbi.nlm.nih.gov/articles/PMC10564111/) The Arnsten neurophysiology is robust mechanism-level evidence but does not connect to intervention longitudinal data. The wage premium establishes market pricing, not a training-to-outcome pathway. ↩
-
Klein, G.A., Calderwood, R. & Clinton-Cirocco, A. (1986/2010). Cited in Klein's RPD model research. Journal of Cognitive Engineering and Decision Making. https://journals.sagepub.com/doi/abs/10.1518/155534310X12844000801203; https://www.gary-klein.com/rpd ↩ ↩2
-
Duckworth, A.L. et al. (2007). "Grit: Perseverance and Passion for Long-Term Goals." Journal of Personality and Social Psychology, 92(6), 1087–1101. https://www.researchgate.net/publication/6290064_Grit_Perseverance_and_Passion_for_Long-Term_Goals ↩
-
Grant, A. (2021). Think Again: The Power of Knowing What You Don't Know. Viking. "Confident humility" defined as revision-openness under evaluative scrutiny — a regulatory capability distinct from baseline intellectual humility in low-stakes reflection. ↩
-
Spence, M. (1973). "Job Market Signaling." Quarterly Journal of Economics, 87(3), 355–374. ↩
-
Ericsson, K.A., Krampe, R.T. & Tesch-Römer, C. (1993). Psychological Review, 100(3), 363–406. https://psycnet.apa.org/record/1993-40718-001 ↩ ↩2
-
Macnamara, B.N. & Maitra, M. (2019). "The role of deliberate practice in expert performance: revisiting Ericsson, Krampe & Tesch-Römer (1993)." Royal Society Open Science, 6(8). The 10,000-hour figure explains a smaller share of performance variance in non-musical domains; the time-gating structural argument is maintained but quantitative precision should be held at directional. ↩
-
Topel, R. (1991). "Specific Capital, Mobility, and Wages." Journal of Political Economy, 99(1), 145–176. NBER Working Paper 3294: https://www.nber.org/papers/w3294 ↩ ↩2
-
ALM New Partners Survey 2021, covering 350 attorneys. Reported in Above the Law, November 2021. https://abovethelaw.com/2021/11/it-takes-longer-than-ever-to-make-it-to-biglaw-partner/ ↩ ↩2
-
BLS OES May 2024, Management Occupations. https://www.bls.gov/oes/tables.htm ↩ ↩2
-
Autor, D., Levy, F. & Murnane, R. (2003). "The Skill Content of Recent Technological Change." Quarterly Journal of Economics, 118(4), 1279–1333. https://academic.oup.com/qje/article-abstract/118/4/1279/1925105 ↩
-
Autor, D. (2014). "Skills, Education, and the Rise of Earnings Inequality Among the 'Other 99 Percent.'" Science, 344, 843–851. https://www.science.org/doi/10.1126/science.1251868 ↩
-
McKinsey Global Institute (June 2023). The Economic Potential of Generative AI. https://www.mckinsey.com/capabilities/tech-and-ai/our-insights/the-economic-potential-of-generative-ai-the-next-productivity-frontier ↩ ↩2
-
PwC (2025). Global AI Jobs Barometer. https://www.pwc.com/gx/en/news-room/press-releases/2025/ai-linked-to-a-fourfold-increase-in-productivity-growth.html ↩ ↩2
-
BLS OES May 2024, SOC 41-3031 (Securities, Commodities, and Financial Services Sales Agents). https://www.bls.gov/oes/current/oes413031.htm; SOC 41-2031 (Retail Salespersons). https://www.bls.gov/oes/current/oes412031.htm ↩ ↩2
-
Moorman, C., Deshpandé, R. & Zaltman, G. (1993). "Factors Affecting Trust in Market Research Relationships." Journal of Marketing, 57, 81–101. https://journals.sagepub.com/doi/abs/10.1177/002224299305700106 ↩ ↩2
-
Weitz, B.A. & Bradford, K.D. (1999). "Personal Selling and Sales Management: A Relationship Marketing Perspective." Journal of the Academy of Marketing Science, 27(2), 241–254. https://journals.sagepub.com/doi/abs/10.1177/0092070399272008 ↩
-
McKinsey Global Institute (2023). The Economic Potential of Generative AI. https://www.mckinsey.com/capabilities/tech-and-ai/our-insights/the-economic-potential-of-generative-ai-the-next-productivity-frontier ↩
-
B2B enterprise software sales cycle benchmarks. Cited from research brief; primary source: Aexus industry research. https://aexus.com/how-long-is-the-average-b2b-software-sales-cycle/ ↩
-
Cambridge Associates US Venture Capital Index data, cited in Kauffman Foundation analysis. Power-law distribution: 1–3 investments generating 50–80% of fund returns. Source: pipeline-road.com analysis of USVC Benchmark. ↩
-
Kauffman Foundation (2012). "We Have Met the Enemy and He is Us." https://www.kauffman.org/wp-content/uploads/2012/05/we_have_met_the_enemy_venture_capital_report_kauffman_foundation.pdf ↩ ↩2
-
Wasserman, N. (2008). "The Founder's Dilemma." Harvard Business Review, February 2008. 3,600-startup dataset. https://hbr.org/2008/02/the-founders-dilemma ↩
-
Kahneman, D. & Klein, G. (2009). "Conditions for Intuitive Expertise: A Failure to Disagree." American Psychologist, 64(6), 515–526. https://psycnet.apa.org/record/2009-13007-001 ↩ ↩2
-
Wasserman, N. (2003). "Founder-CEO Succession and the Paradox of Entrepreneurial Success." Organization Science, 14(2), 149–172. https://pubsonline.informs.org/doi/10.1287/orsc.14.2.149.14995 ↩